Source: Intelligent World 2035 (Huawei, 2025)
— Included in Data Dialogue, Issue 002
I. Data awakening: AI will enable long-term retention and turn cold data into warm data requiring efficient processing
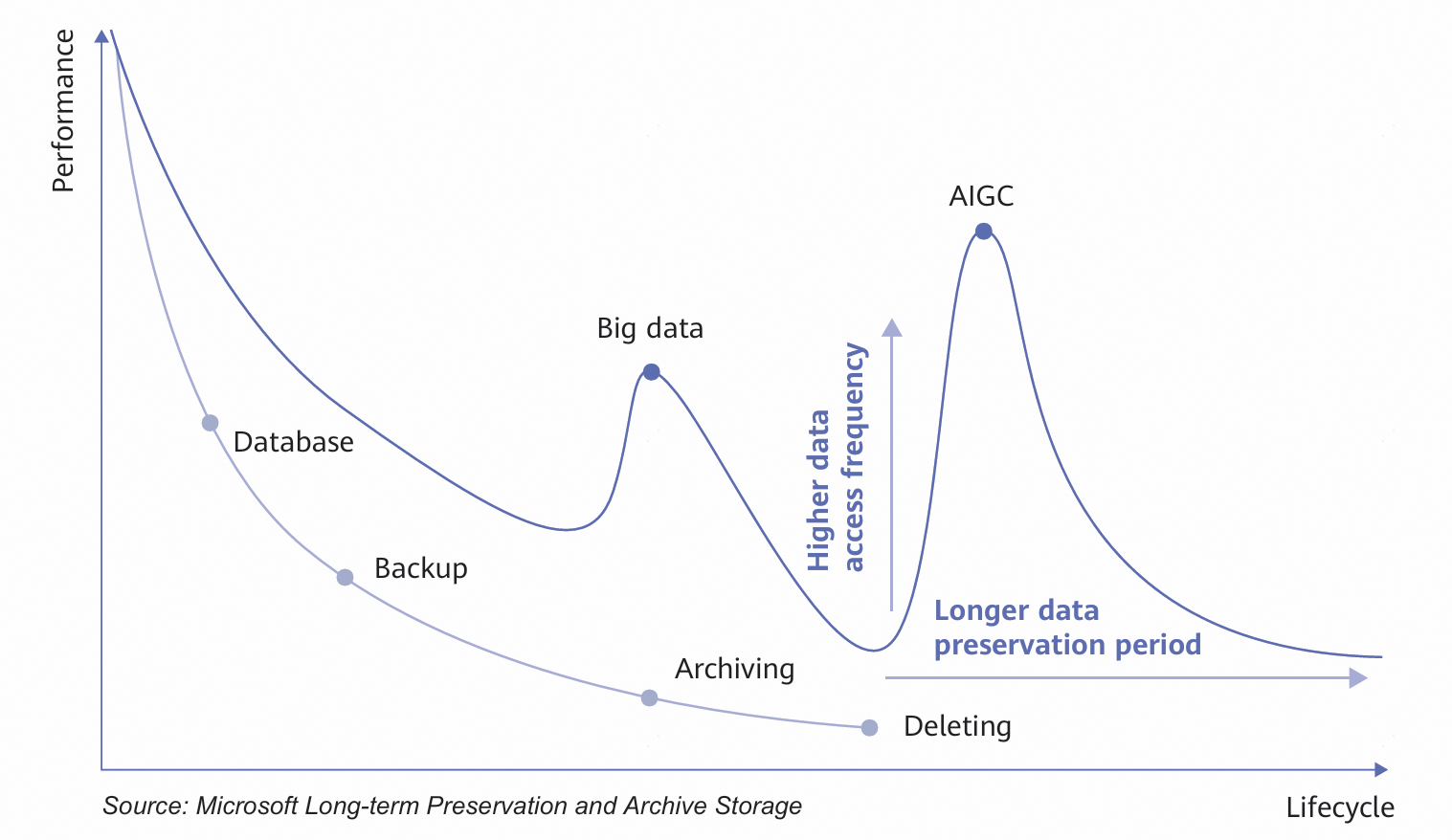 Figure 1 Changes in data lifecycle
Figure 1 Changes in data lifecycle
AI model training and inference are driving explosive growth in data access. Much of the data once considered cold data is now being reactivated, transforming into warm data, and even hot data, as it is increasingly used for model iterations and real-time inference. We forecast that by 2035, the traditional three-tier model— hot, warm, and cold data—will shift to a new two-tier architecture: a hot/warm tier and a warm/ cold tier in a 3:7 ratio. This means warm data will account for more than 70% of all data by 2035.
This major shift will significantly enhance data utilization, and allow businesses and civil society to unlock unprecedented value from historical data. Ultimately, data will transform from a passively stored resource into an active enabler.
In the age of AI, unlocking the value of data has become more important than ever, yet long-term data retention still poses numerous challenges. The first is cost and efficiency. There is a large volume of warm data that needs to be frequently accessed. Any delays or low throughput will directly extend model training cycles, slow down AI agent responses, and drive up computing and time costs.
Second, data timeliness is critical. AI applications (e.g., autonomous driving and real-time decision systems) demand millisecond-level access to relevant memory and contextual data. Slow I/ O operations and data processing can become severe performance bottlenecks that disrupt real time interactions in practical scenarios.
More importantly, long-term data retention is not for data hoarding but instant insight generation. Value density and extraction speed remain a key challenge. Efficient processing means quickly locating, associating, and extracting high-value information from vast amounts of warm data, and then converting this information into model intelligence or action commands. This makes data the fuel for intelligent decision making rather than a burden on storage systems. Efficient processing of massive warm data is essential for maximizing the value of AI.
II. Data-driven intelligence: Data defines model intelligence, while memory defines the scope of agentic applications
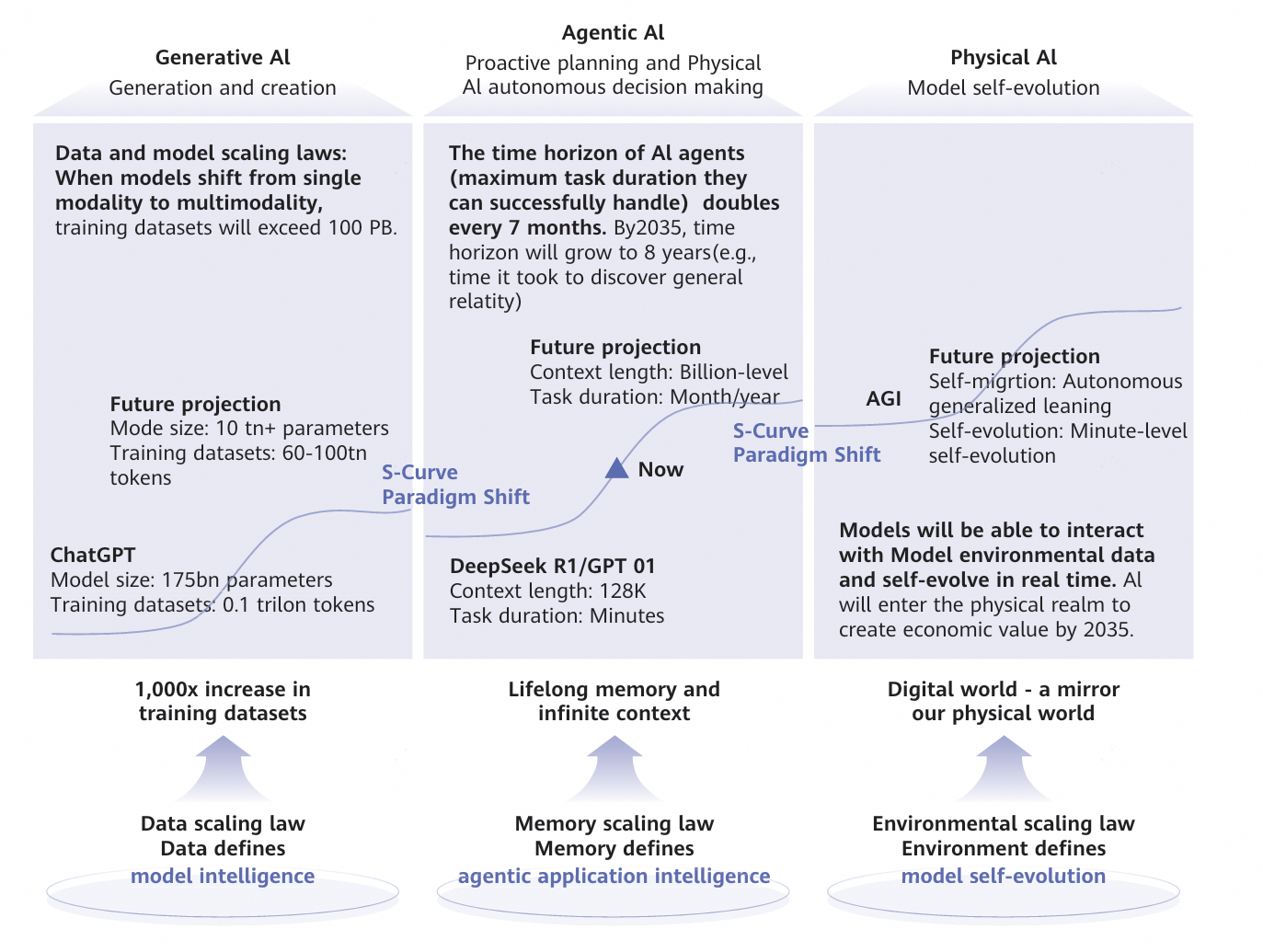 Figure 2 Data scaling laws: Data-driven model intelligence
Figure 2 Data scaling laws: Data-driven model intelligence
The development of AI models is undergoing a strategic shift from being parameter-centric to data-centric. Early Generative AI relied heavily on massive training datasets–often reaching petabyte scales–while the marginal gains from increased parameter counts have progressively diminished. In the era of Generative AI, data capabilities are primarily reflected in the scale of training data, which is growing from 0.1 trillion tokens for ChatGPT to an anticipated 60–100 trillion tokens in the future, with total training data volumes exceeding 100 petabytes.
In the Agentic AI era, data-capability requirements will evolve in three key areas:
First, AI interactions will go from being stateless to stateful, meaning a transition from reactive responses to active planning, reflection, and iteration. Such changes will enable AI to handle complex tasks on their own. During inference, model states will be continuously updated, thus requiring the storage of petabyte-scale state data and support for millions of concurrent queries. Additionally, knowledge extraction will facilitate continuous model self-evolution. Second, AI will progress from standalone agents to interconnected multi-agent systems, where close collaboration will be essential to deliver cluster intelligence. Multi-agent task execution requires sharing task states and historical context, with data being transferable across tasks.
Third, single-session memory will evolve into continuous, cross-session persistent memory. The growth rate of personalized, lifelong memory data is expected to rise from 10 Gbit/s to 1 Tbit/s, generating hundreds of petabytes of persistent memory and enhancing the intelligence, accuracy, and generalization capabilities of Agentic AI.
In the Physical AI era, data will create a mirror of the physical world in the digital world in real time. Through frequent interaction with environmental data, AI systems will dynamically self-evolve. Rather than relying on pre-labeled datasets, AI systems will continuously refine performance via real-time perception and feedback loops.
By 2035, digital twins, embodied AI, and super agents will be widely adopted, increasing demand for AI storage by 500 times, and AI storage will eventually account for more than 70% of global total storage capacity.
III. The next storage paradigms: From data to knowledge
The basic paradigm of data storage is currently undergoing a profound transformation to meet the demands of AI models for data logic and semantic relationships. Traditional storage methods, based on files and objects, are struggling to meet AI's requirements for data correlation, statefulness, and adaptability. In the past, files or objects were treated as closed, static units, with storage systems primarily focused on ensuring integrity, durability, and retrievability. AI applications, by contrast, process and interpret information dynamically, contextually, and with evolving states, which is fundamentally at odds with traditional storage approaches. The future evolution of data storage will be characterized by several key shifts:
l Data correlation: AI requires a deep understanding of the complex semantic relationships within data. During training and inference, AI agents need to rapidly retrieve the most relevant historical segments for a given session. Traditional file systems store data in isolated files and directories, with semantic relationships being implied and undocumented. This means significant computing power will be needed to reconstruct these relationships each time. Future storage paradigms will embed pre-computed associations, such as key-value caches and knowledge graph triples, directly within the data to make it intrinsically contextually associated.
l Statefulness: Agents have continuous memories, and their value can largely be attributed to their evolving states, covering areas such as interaction history, task execution progress, and preferences learned from previous interactions. Conventional file systems store results, whereas AI processes must keep reading, writing, and updating states. Frequently updating state data on a file-by-file basis is extremely inefficient. Therefore, future storage system designs will need to account for finer grained and frequently-updating states, and the systems will have to directly manage agents' memory streams.
l Evolvability: Continuous learning and fine tuning are the standard for AI models, meaning the models' key knowledge (usually represented as "weights") constantly changes on an incremental basis. The conventional method is to store an entire replica of the model–a practice that leads to significant redundancy. Efficiently storing and retrieving weight updates is more practical, as only the changes will be stored. This approach will allow model knowledge to be managed in a leaner, version based manner, and support rapid rollback to reduce the cost and complexity of model iterations.
The value of data is currently defined by the data volume and storage formats. By 2035, new value differentiators will be technologies that turn cold data into warm data, supply the right types of data for the right scenarios, and support semantic storage. When this happens, data will become more than just memories, but a new type of fuel that propels human progress. Storage systems will evolve from data warehouses to engines that drive AI advancements. Data, plus computing power and algorithms, will remain key pillars of our future intelligent world.
Access Data Dialogue, Issue 002 →

