
With the rapid development of AI big model technology, the problem of data Island has become the key to restrict its progress. The AI data lake solution launched by Huawei effectively integrates data storage, management and services through an innovative three-tier architecture, and solves the problem of data collection and preprocessing, provides powerful data support for AI big model training.
Since C hatGPT was released in November 2022, AI big model technology has developed rapidly. AI big model training is becoming the core force to promote technological progress. However, the exponential increase in data volume and types brought about by the development of AI models has led to the prominent problem of data Islands, which has covered people's pursuit of light like fog. With its AI data lake solution, Huawei provides a clear path for AI model training, which not only connects data islands, but also accelerates the emergence of intelligence, illuminates a new era of artificial intelligence innovation and development.
Artificial intelligence is setting off a global wave. At the end of 2023, Google released the Gemini Multi-modal model, which can understand, operate and combine different types of information, including text, code, audio, image and video. In February 2024, openAI releases the Sora video model. By combining the diffusion model and the big language model, it "emerges" three-dimensional consistency in the learning process of the physical world, making Wensheng video very realistic.
The development speed of AI models is far faster than people expected. From ChatGPT to Gemini and then to Sora, two development trends can be observed:
trend 1: as the big model moves from NLP to multi-mode, the original training data set and data training material change from plain text to a mixture of text, view, image and voice, the amount of data on which big model training depends increases exponentially, with an expansion of 10,000 times.
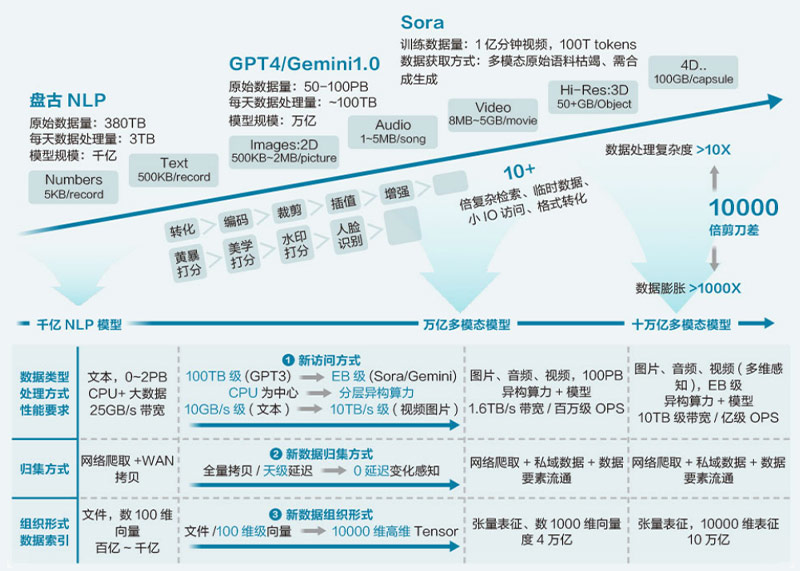
Multi-mode brings exponential growth of training data
trend 2: big model develops the computing power, algorithm and data of the core three elements, showing a violent aesthetics of "vigorously creating miracles. That is, through heap computing power, Heap data, and increase the parameter scale (from 100 billion to 1 trillion or even 10 trillion), complex behaviors can emerge under the framework of deep learning algorithms. In the video of fashionable ladies walking on the street released by Sora, the Street View (neon advertisements, pedestrians, etc.) behind the ladies is blocked from time to time, but before and after the blocking, these streetscape maintain good three-dimensional consistency, restoring the human eye's actual perception of the real world.
With the rapid development of AI big model technology, everyone has witnessed the leap from single mode to multi-mode, but the following massive data challenges, an innovative solution is urgently needed to integrate scattered data resources. Because, as a way of presenting the real world, data is the basis of AI big model training, especially with the blessing of deep learning algorithm "making great efforts to achieve miracles, the scale and quality of data play a vital role in improving the training effect. However, the current reality is that most data owners only care about whether business applications can access data efficiently, and do not care about where the data is stored; however, most data managers only care about whether the data is effectively stored, and do not care about whose data it is or what type of data it is. This makes data scattered in multiple data centers, forming an isolated island of data. Take an operator as an example. The total amount of data accumulated over the years has reached hundreds of PB, and now hundreds of TB of data are generated in real time every day, scattered across multiple data centers. In order to provide as many data training materials as possible for AI big model training, the technical department of the operator has to migrate or copy the data of these data islands across regions, as a result, the time spent preparing data accounts for more than 50% of the whole process of big model training.
How to break the isolated data Island, effectively and quickly collect scattered data, quickly convert the collected data set into AI big model training materials, allow data training to be efficiently accessed by AI computing power...... These problems have become the biggest challenges and primary considerations in the construction of AI big model infrastructure.
The ideal AI data infrastructure should aim at the key links of AI big model training, such as data collection, data preprocessing, and model training, to provide high-quality data services. To achieve this goal, at least two levels of data infrastructure should be considered comprehensively: the storage device layer and the data management layer.
Storage device layer
in the face of multi-source heterogeneous and massive data, especially in multi-modal AI training scenarios, the ideal storage device layer should have the characteristics of multi-protocol intercommunication, high read/write, and easy expansion, to meet multiple challenges and support the following key steps of AI model training:
data management
based on the International Data Space Reference Architecture (IDS-RAM) and China trusted industrial data space (TIDM) system architecture, the financial data trusted circulation solution adopts Huawei data storage products and solutions such as DCS and FusionCube, by introducing key technologies such as data security modeling and access control core algorithms, quantum key distribution, and enterprise data space, and combining high-performance data usage control engine, data transparent encryption and decryption, hardware trusted execution environment, security features such as evidence-keeping and tracing ensure the reliability and controllability of data transmission across subjects and borders, protect the rights and interests of data owners, and promote the maximum superposition and multiplication of data elements in the financial field.
Overall, the core capabilities of an ideal AI data infrastructure (as shown in the figure)

core capabilities of AI data infrastructure
to sum up, there are three points as follows:
huawei has actively cooperated with customers in AI big model training in many industries including operators, and has accumulated rich practical experience in data infrastructure in AI field over the years. Based on this, Huawei recently launched an AI data lake solution to help customers solve problems encountered in deploying and implementing AI big model training data infrastructure, let Customers focus more on their own big model development and training. The architecture diagram of Huawei's AI data lake solution is divided into three layers: Data storage layer, data weaving layer, and data service layer.
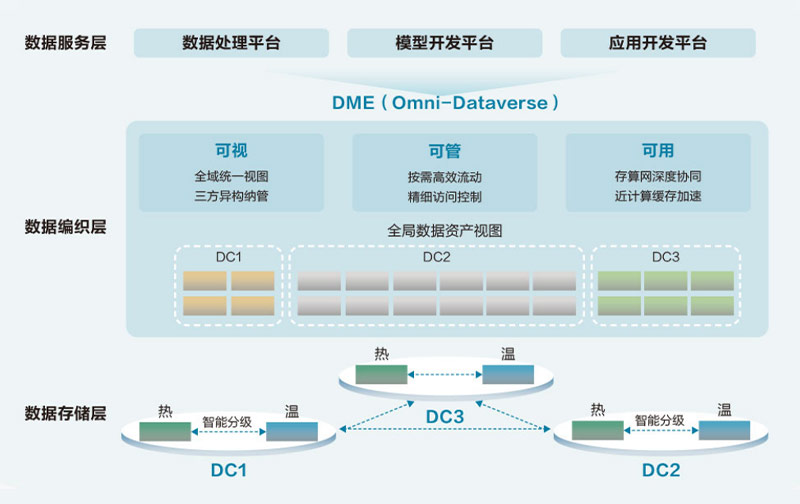
Design of Huawei AI data lake solution architecture
data storage layer
at this layer, data is stored in multiple different data centers.
Inside the data center, data is intelligently graded at the hot and warm levels. The hot layer is actually the OceanStor A series of high-performance storage designed by Huawei for AI big model training business scenarios, which can be scaled up to thousands of nodes. The warm layer is the OceanStor Pacific series of distributed storage of Huawei, used for massive amounts of unstructured data. Between the OceanStor A series and the OceanStor Pacific series, intelligent grading can be realized, that is, within the same storage cluster, multiple A series nodes form A high-performance storage layer, while Pacific series nodes form A large-capacity storage layer, the two layers are combined into one, and a complete file system or object bucket is displayed externally, which supports multi-protocol communication (a piece of data can be accessed by multiple different protocols), and the internal is intelligently, automatically performs data grading, which satisfies the harmony and self-consistency of capacity, performance and cost at the same time.
Data centers can create data replication relationships between different storage clusters to support highly reliable data flow across data centers, it supports the data collection of AI big model training at the data device layer.
Data weaving layer
the meaning of "data weaving" is to pave a mobile network of "traffic across the streets" for data, making data visible and manageable, thus maximizing the value in the AI model training process.
Through a software layer Omni-Dataverse, Huawei realizes the visible and manageable availability of data. Omni-Dataverse is an important component of Huawei's Data Management Engine (DME). Through unified Management of metadata stored in Huawei in different Data centers, A global view of data assets is formed, and data flow is controlled by calling interfaces on storage devices (Omni-Dataverse perform related actions based on user-defined policies). In addition, Omni-Dataverse can also control GPU/NPU direct-through storage and intelligent prefetch of files on demand, allowing computing power to wait for training data.
In this way, the efficiency of data collection and model training during AI big model training is improved, thus supporting the improvement of cluster availability.
Data service layer
huawei's AI data lake solution provides common service frameworks at the data service layer, including data processing, model development, and application development.
Data processing, mainly provides data cleaning, conversion, enhancement, standardization and other preprocessing actions. Big Model customers can integrate their own algorithms and functions into it, and use this framework to simplify the management of the preprocessing process. Of course, customers can also flexibly choose to use other frameworks.
Similar to data processing, model development and application development are frameworks for user convenience. Customers can make flexible choices according to their own needs.
Huawei's AI data lake solution is Huawei's experience in AI big model training, helping enterprises break data islands and realize free data circulation, data weaving is implemented between data applications and storage devices to make data visible and manageable. With the continuous evolution of AI models from single mode to multi-mode, the increase of data volume and data type will inevitably lead to the non-linear increase of management complexity and performance requirements. The three-tier AI data lake solution, it can effectively cope with the corresponding increased complexity and performance requirements, continuously assist the development of AI big models, accelerate the emergence of intelligence in big model training, and push the innovation and development of artificial intelligence to a new height.
