
Ji Xu | CTO, Nanjing Cornerstone Data Technology Co., Ltd.
"A storage engine is essential to process storage tasks and manage data in the database management system. LSM-trees and B-trees/Heaps are two storage structures designed for distributed and conventional general-purpose databases, but neither is perfect. LSM-trees are suited for high-concurrency writes but with poor read performance, whereas B-tree and Heap structures deliver better performance for data reading and complex queries but experience bottlenecks on concurrent writes. Each database type has its advantages and drawbacks, including single-server centralized databases, distributed databases, and shared storage with a multi-primary architecture. Oracle RAC stands out as the most application-friendly option due to its shared storage with a peer-to-peer read/write architecture. Huawei's open-source Cantian engine is middleware that equips single-server databases with capabilities similar to Oracle RAC. It supports the InnoDB storage engine, offering a convenient solution for implementing RAC-like architectures."
Storage engines are used for processing storage tasks and managing data, including data storage, retrieval, updating, and deletion. Different engine options are available to meet the specific needs of various application scenarios. Indeed, a storage engine can directly influence the base performance of any database.
Based on the underlying data structures and data organization methods, the most common storage engines for databases can be grouped into two categories: log-structured merge-tree (LSM tree) for distributed databases and B-tree and Heap for general-purpose databases. B-tree and Heap storage are highly similar and are often considered interchangeable in many cases. Databases such as Oracle, PostgreSQL, and MySQL all run on B-tree or Heap structures. (Note: B-tree is used here as a common identifier, though the actual data structure is an enhanced B+ tree).

Two types of database storage engines
The graphic above (source: Internet) displays two types of database products. Traditional and centralized databases predominantly utilize the B-tree structure, whereas distributed databases often employ the LSM-tree structure. LSM-tree structures are immutable, meaning they reduce the cost of finding existing pages before writing new data, enabling higher write concurrency than mutable structures. This makes LSM-tree databases ideal for high-concurrency write and modification operations. However, their need for coordination among copies can impact read performance.
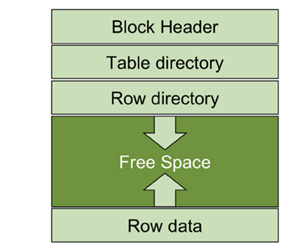
Oracle block structure with a typical slotted page (Heap) format
Heap structures are similar to B-trees, but with distinct differences. Commonly used databases such as Oracle and PostgreSQL use the Heap structure with slotted pages, whereas common examples of B-tree models include MySQL and Dameng databases.
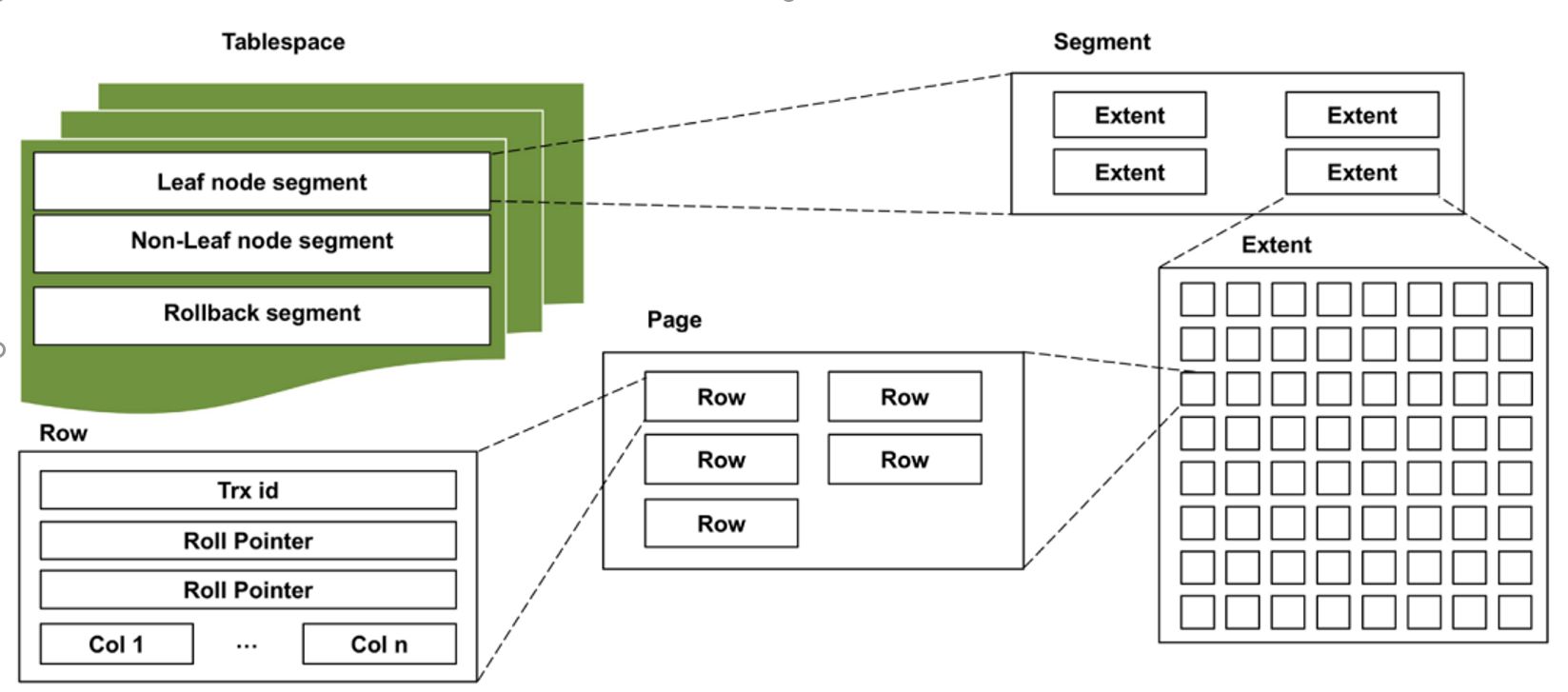
B-tree storage structure of MySQL
The figure shows the logical layout of the MySQL InnoDB storage engine. However, B-tree structures differ between storage engines, particularly in whether data is stored in leaf node segments. For example, MySQL stores both together, while Dameng stores them separately. In a B-tree, data is organized by primary key, ensuring efficient retrieval.
Where many storage engines use similar data organization methods, Oracle supports various table types, including Heap, cluster, and hybrid column compression tables. Among these, cluster tables use the B-tree structure. Dameng storage engine uses B-tree data as the default organization mode for common Dameng tables, while also supporting heap table data, column-store data, and bitmap indexes.
When it comes to storage engine structures, people often claim that newer structures are superior to traditional ones, but in reality, even the most advanced storage engines have their limitations. What is considered 'advanced' is simply a feature introduced later in the development process. Despite decades of progress, the storage engine landscape has not seen a proliferation of vastly different types.
LSM-trees are widely used thanks to the significant reductions in memory costs. Memory tables (memtabs) boost performance for high-concurrency writes and sorted strings tables (SSTables) improve persistent storage efficiency and data compression. LSM-trees gained traction in online transaction processing (OLTP) relational databases following the breakthroughs in SSDs. Before then, the high overhead of post-process compression could cause instability and make it unsuitable for latency-sensitive OLTP systems. The advent of SSDs made all the difference.
B-tree and Heap structures typically use In-Place-Replace that provides stable performance, even with resource wastage from page fragmentation (with the exception of PostgreSQL's ASTORE). However, during concurrent writes, B-trees are more likely to encounter performance bottlenecks compared to LSM-trees. For example, in scenarios where hundreds of millions of data records are concurrently written every 5 minutes, and real-time statistics and analytics are required, performance improvements become increasingly difficult once B-tree-based databases (e.g., Oracle) exceed 10 million records per second. In contrast, distributed databases using LSM-trees can effortlessly handle over 20 million records per second. Though B-trees may not match LSM-trees in write performance, they excel at data reading, MVCC, and complex queries.
Determining which structure is superior will depend on where it is used. For example, LSM-trees are more compact and prevent data fragmentation, whereas B-tree engines may write only small portions of data per page, leading to write amplification. Although LSM-trees do not inherently suffer from write amplification, this issue can be caused by the frequent merging of underlying SSTables in high-throughput write scenarios. Modern hardware's significant improvements in write I/O capabilities have mitigated this issue in most scenarios.
Other contributing factors go beyond the underlying data organization. As one of the key core engines within a database, the primary functions of a storage engine include:
l Data storage: Stores data on disks or other storage media.
l Data retrieval: Retrieves data quickly and efficiently based on search criteria.
l Data update: Inserts, updates, and deletes data.
l Transaction management: Ensures transaction atomicity, consistency, isolation, and durability (ACID), maintaining data consistency and integrity.
l Concurrency control: Ensures data consistency and integrity during simultaneous access by multiple users.
l Data backup and recovery: Supports data backup and recovery, ensuring data resilience.
Therefore, a high-performance database requires more from its storage engine than just its storage organization. Modern databases come in various forms, including single-server centralized databases, shared storage databases (read/write splitting or multi-primary), and distributed databases, each with unique storage engines.
The single-server centralized database features a streamlined architecture that is applicable to many scenarios and easy to operate and maintain, making it a popular option for many users. Its single-server basis means it supports only scale-up, not scale-out, making it a bottleneck in business expansion plans. In addition, such databases can only use primary-secondary replication for high availability. If the primary database fails, the low automation and slow failover may not meet the needs of core systems.
Distributed databases address some of these issues but still face other, more complex challenges. Furthermore, cluster network latency can impact performance, such as reducing storage efficiency. As a result, such solutions are typically used in systems with ample budget resources.
Shared storage databases running multi-primary architectures are popular today, as exemplified by Oracle RAC. Multiple compute nodes share a centralized storage system, minimizing resource waste. The scale-out of the cluster nodes ensures the service capacity can be scaled linearly so that, if a node fails, applications can be automatically failed over to healthy nodes within seconds, providing robust reliability for enterprise applications. The database is centralized, which simplifies application development and O&M.
The multi-primary architecture of shared storage has high demands on the storage engine, specifically in terms of buffer convergence, global lock management, global resource catalog, global transaction management, and global consistency recovery. For this reason, few database products other than Oracle provide this architecture.
At Database Technology Conference China (DTCC) 2023, Huawei released a MySQL shared storage solution with concurrent read/write that runs on a core of the Huawei Cantian engine. This solution has been open-sourced under the project openEuler/Cantian within the Mulan community. The Cantian engine is middleware that equips common single-server databases with capabilities akin to Oracle RAC. The current version supports InnoDB and will expand to additional database storage engines in the future. It adopts a decoupled storage-compute architecture and leverages key technologies such as distributed cache, multi-version concurrency control (MVCC) for transactions, and high availability in a multi-active cluster. This enables multi-primary capabilities for common single-server databases. The Cantian engine can be seamlessly loaded and executed by systems like MySQL without requiring modifications to the existing database implementations. Cantian has been recognized by top finance companies and carriers, winning the IT168 2024 Technology Excellence Award.
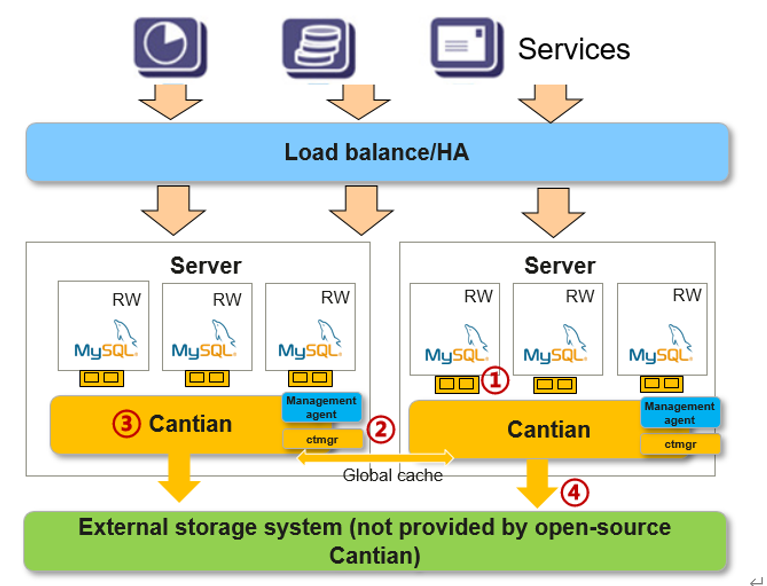
The preceding figure shows the logical architecture of Cantian, developed on Huawei OceanStor Dorado high-end storage system and acting as a middle layer between the MySQL engine and the InnoDB storage engine. It simulates InnoDB's behavior, enabling seamless integration to MySQL engine. Because InnoDB is closely related to transaction control, Cantian combines the MySQL storage layer and transaction management layer, which enables MySQL to perform concurrent read and write operations on multiple nodes and ultimately become a MySQL RAC. As an open-source engine, Cantian extensively references successful practices of Oracle RAC to mitigate the cross-instance consistent read/write issue, serving as a benchmark for future shared storage databases running multi-primary architectures.
In summary, the storage engine is the core component of the relational database management system (RDBMS), as it determines many capabilities of the database. Even with modern advances, however, no storage engine is perfect, as modern database systems are more complex than simple software systems. It is important to find modern hardware that mitigates the engine's drawbacks and enhances its strengths. In this space, Cantian provides a useful reference for future developments. Furthermore, databases should be determined based on the storage engine's strengths and limitations to meet the specific needs of the use case.
Source: Data Dialogue (2025 Jan. issue)
