黄俊| 某证券公司 核心系统架构师
—— 本文收录于《话数 · 第3期》
【摘要】在金融行业全面信创的落地过程中,证券公司作为资本市场的核心枢纽,其核心交易系统的自主可控、高性能运行直接关系到金融市场的安全与稳定。不同于普通行业,证券交易系统对低时延、高可靠、高并发有着极致要求——毫秒级的性能差异都可能影响客户交易成交概率,系统稳定性更是容不得丝毫闪失。然而,在 CPU、存储、交换机、网卡等底层关键硬件全面国产化替代的过程中,性能与稳定性的不确定性增加、调优职责真空等痛点问题日益凸显,传统研发协作模式已难以为继。
大模型技术的崛起,为证券信创全栈调优带来了革命性机遇。通过融合 RAG(Retrievalaugmented Generation,检索增强生成技术)[1]、模型微调 [2]、MCP(Model Context Protocol,模型上下文协议)[3] 等前沿技术,构建全流程闭环的智能调优体系,能够切实有效地缓解国产化替代进程中的性能差距问题,加速实现“稳、快、省”的核心目标。本文将结合我司核心交易系统全面信创实践,深入探讨大模型在全栈智能调优中的技术路径与落地价值。
一、信创落地的双重困境:性能鸿沟与职责真空
-
全栈组件性能差异:稳健替代的隐形障碍
国产软硬件与国外竞品的性能差距在证券核心交易场景被放大,形成了多层次“性能鸿沟”:计算层面,国产 CPU 在核数密度、单核性能、多核协同等方面与国外高端竞品存在较大差距;网络层面,国产交换机与高性能网卡在微纳秒级低时延场景难以匹敌 Mellanox等国际前沿产品;操作系统领域,以欧拉 OS为基座,以银河麒麟、统信 UOS、麒麟信安、浪潮云启等商务发行操作系统做商用增强的开源 + 商务发行模式已形成成熟闭环,但在内核优化、虚拟化与容器化支持能力、硬件兼容性与驱动支持广度、开发者工具链与社区规模等方面依然存在差距;数据库、JDK、通用中间件等领域,在产品成熟度、上下游工具链、技术生态、跨平台兼容性等方面仍有较大提升空间。全栈组件性能差异叠加,使传统粗放型调优方案效果欠佳,亟需精细化调优弥合差距。
-
组织架构制约:调优职责的真空地带
传统“开发 - 运维”组织分离的企业研发模式,开发团队侧重业务编码实现,缺乏底层调优技术积累,运维团队聚焦系统运行稳定性,缺乏主动调优的内生动力与绩效机制支撑。然而,信创系统全面落地,既要“跑得稳”,也要“跑得快、省资源”,要求技术团队兼具业务逻辑理解能力与全栈技术能力。当前这种“谁都不负责、谁都不会做”的技能缺失与职责真空问题,导致国产软硬件性能潜力无法充分释放。
-
转型机遇:云原生与大模型的双重赋能
挑战背后往往潜藏着机遇。云原生(云计算 3.0)时代的研发组织与技术变革、大模型技术的飞速发展,为信创全栈调优提供了坚实的技术可行性基础:1) 软件定义硬件技术的普及打破了过往软硬件的物理隔阂关系,计算、存储、网络等传统 IaaS 三大件都已支持虚拟化,具备软件定义能力,为全栈精细化调优提供了底层技术支撑;2)DevOps 产研运一体化运作正快速推动企业研发组织架构变革,打破了开发与运维的部门墙,为调优职责落地创造了组织条件;3)传统基于策略算法的调优闭环(Agent 数据采集、问题专家诊断、方案手工生成、参数自动下发)已得到充分生产实践验证,为智能调优闭环提供了流程设计参考;4)大模型技术能提供核心推理引擎,其动态负载感知、智能决策能力,可有效应对信创软硬件环境超 13000 个调优参数的“高维轰炸”,再通过 RAG、模型微调、模型蒸馏等技术解决了知识集成、轻量化部署等问题,使全栈调优从依赖专家经验的“纯手搓艺术”变成“批量化、自动化”的流水线作业成为可能。
二、大模型赋能调优:技术原理与核心突破
-
传统贝叶斯调优方法的局限
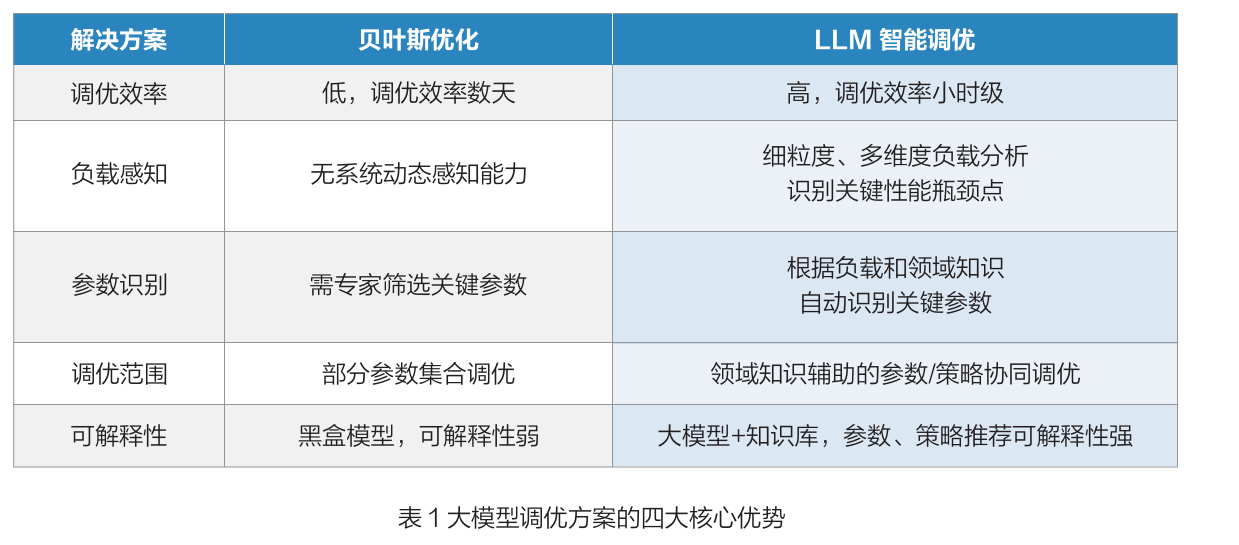
贝叶斯优化 [4] 是参数调优领域的经典框架,通过贝叶斯定理整合历史观测数据,指导参数搜索过程,具有高效性、自适应性等优点,在传统调优场景中得到广泛应用。但在全栈信创场景中遭遇到明显瓶颈——高维参数空间下搜索效率急剧下降,初始关键参数的筛选严重依赖专家经验,概率模型的“黑箱”特性导致方案可解释性不足,且无法动态适配交易系统潮汐式负载变化,难以满足全栈调优需求。
-
大模型调优的核心技术:多维度能力融合
大模型调优方案并非全盘否定传统调优框架,而是通过整合四大核心技术实现关键环节的自动化能力升级:
1)RAG 技术:通过持续整合技术方案文档、部署手册、运维日志等海量非结构化数据,构建可及时更新的调优领域知识库;而生成的方案内容可附带来源引用,提升可解释性与可信度;同时支持企业私有数据接入,避免内部敏感信息泄露。而针对其检索精度与延迟问题,
则通过知识库质量管控、热点知识缓存等方式优化解决。
2)模型蒸馏:将二次增训的大模型的核心能力迁移至参数量仅为 1/10 甚至 1/20 的中小模型,在保持 80-90% 推理能力的同时,将方案生成时间从十秒级缩短至秒级,甚至可支持极限资源场景下 CPU 模型的本地部署,满足不同资源规格环境的实时调优需求。
3)模型微调:基于信创全栈调优数据集,通过 Adapter Tuning[5]、LoRA[6] 等参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)[7] 技术,对通用大模型进行二次训练,强化其在国产 CPU、欧拉 OS、国产数据库、国产 JDK 等专有领域的调优推理能力,实现专家经验和领域模型之间的高效协同的同时,可有效控制训练成本。
4)MCP 技术:基于 MCP 技术构建“通用大模型 + 多个领域小模型”的分层多模型架构,通用大模型负责简单问题应答、意图理解与任务路由,下层对接 OS、数据库、中间件等领域调优模型,结合脚本下发 Agent 等组件,实现全栈参数协同优化,避免局部优化导致整体性能下降。
-
大模型调优方案的四大核心优势
与贝叶斯调优相比,大模型方案实现关键突破:一是调优范围更广,覆盖从应用层到硬件层的全栈组件;二是效率更高,将数天级调优任务缩短至小时级,效率提升 80% 以上;三是可解释性更强,通过知识库引用与全链路追溯满足严苛评审要求;四是动态适应性更好,支持在线学习,适配不同运行特点的系统负载波动。
三、AITune 调优平台架构与初步落地成效
基于上述大模型方案设想,我们构建了全栈智能调优平台 AITune,初步实现了从性能数据采集、性能瓶颈诊断、优化方案生成到自动优化的全流程闭环,在核心交易系统的信创改造过程中初步取得了不错的落地成效。整体架构设计如下图:
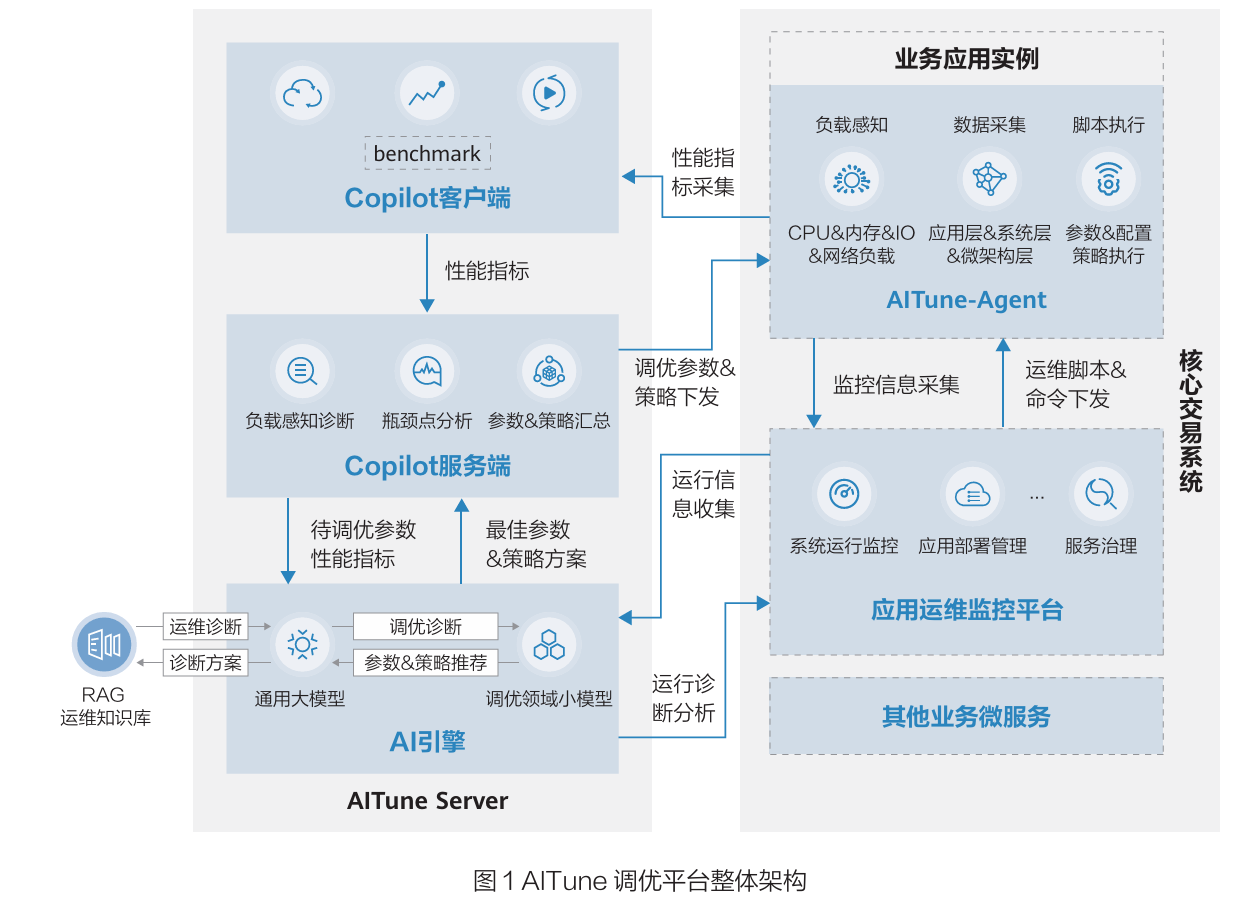
1、AITune调优平台架构
AITune 集成了 openEuler 智能化解决方案 openEuler intelligence( 原 名 Euler Copilot)[8],整体采用 C/S 架构设计,分为采集与执行层、评测层、分析层、决策引擎层四层,实现了全栈数据的贯通与智能调优的自动化:
1) 采集与执行层: 通过将AITuneAgent 部署在各服务器节点,持续采集应用层(系统 TPS、时延、错误率等)、系统层(CPU利用率、内存使用、IO 负载等)、微架构层(CPU 缓存命中率、指令执行效率等)、网络层(网卡吞吐量、时延、丢包率等)等多维度运行数据,并支持脚本自动化执行与参数版本回滚。
2)评测层:以 Copilot 客户端为核心,通过预设的标准化测试用例库,支持对系统层、微架构层、网络层进行多维度性能基准测试。同时支持自定义测试场景扩展,可灵活适配不同业务系统性能评测要求。
3)分析层:以 Copilot 服务端为核心,承担负载感知诊断、瓶颈诊断分析、调优参数 & 策略汇总与下发等职责,负载感知模块与RAG 助手协同运作,通过多维度数据关联分析,识别性能瓶颈点。同时,Copilot 服务端支持将调优参数 & 策略方案转换为操作系统命令、数据库 SQL 语句、中间件配置文件等可执行指令,再批量下发至目标服务器。
4)决策引擎层:是平台的智能核心,集成了通用大模型、调优领域小模型、RAG 运维知识库,以及各 MCP 协同模块。通用大模型负责理解业务场景、性能需求、任务分拆与路由等;各调优领域小模型针对不同领域组件生成专项参数方案,例如 OS 调优模型优化进程亲和性、内存调度策略,数据库调优模型优化连接池大小、索引配置;MCP 协同模块则对各专项工具方案进行整合与冲突校验,确保全栈参数的协同性,避免局部优化导致的整体性能下降。
平台核心创新在于“智能调优自验证回环”设计:通过“数据采集 -> 方案校正与生成 ->策略执行 -> 效果确认与反馈”的闭环迭代,持续优化调优准确性,规避大模型的不确定性,同时支持与现有运维平台深度集成,支持自然语言交互,降低了使用门槛。
2、关键落地成效
AITune 平台已在核心交易系统多场景落地验证,性能提升显著:
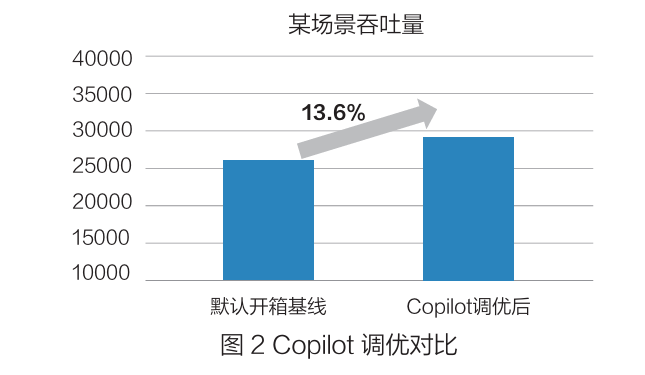
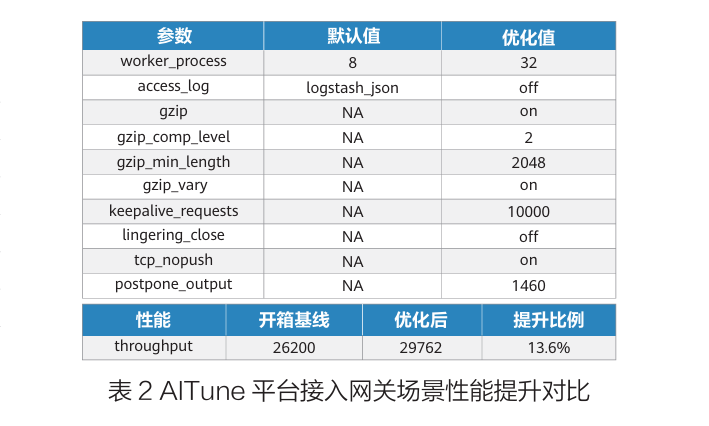
1)接入网关场景:针对类 Nginx 网关的开箱调优,通过识别并调整 worker_process、gzip_comp_level、keepalive_requests 等关键参数,2 小时内将网关吞吐量从 26200 提升至 29762,性能提升 13.6%。如下图所示:
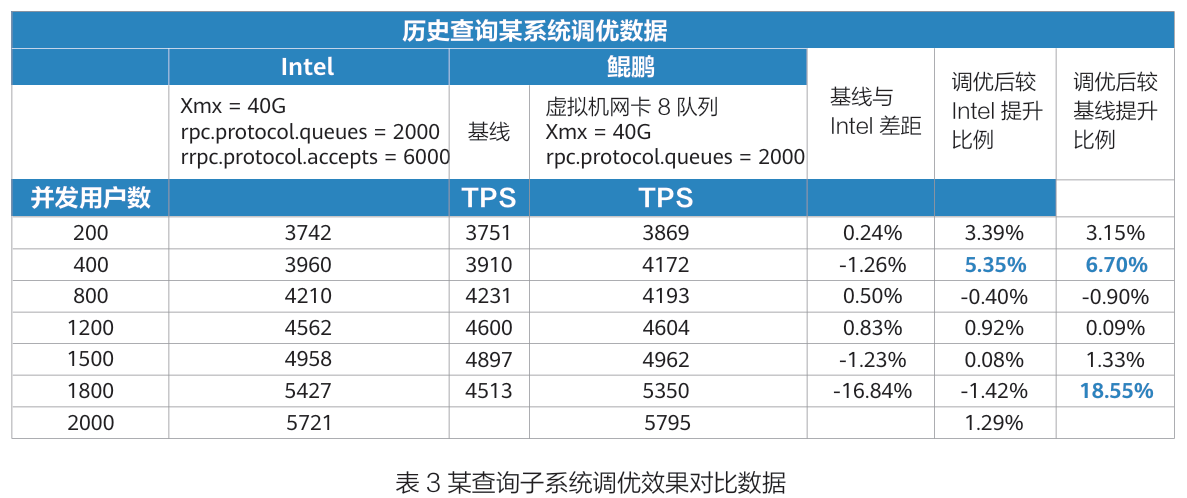
2)历史查询子系统场景:在 1800 并发用户场景下,鲲鹏服务器调优后 TPS 从 4513 提升至 5350,提升比例达 18.55%,不仅弥补了与 Intel 服务器的性能差距,甚至实现了部分超越。
3)期权交易子系统场景:多个核心接口的 TPS 提升幅度超过 40%。资产查询接口调优后TPS 从 34899 提升至 55535.61,提升 59.13%,远超 x86 服务器的 36553.18;交易查询接口调优后 TPS 达 53888.62,较调优前提升 42.21%,较 x86 服务器提升 28.06%;委托数量获取接口调优后 TPS 较调优前提升 54.75%,较 x86 服务器提升 75.92%。
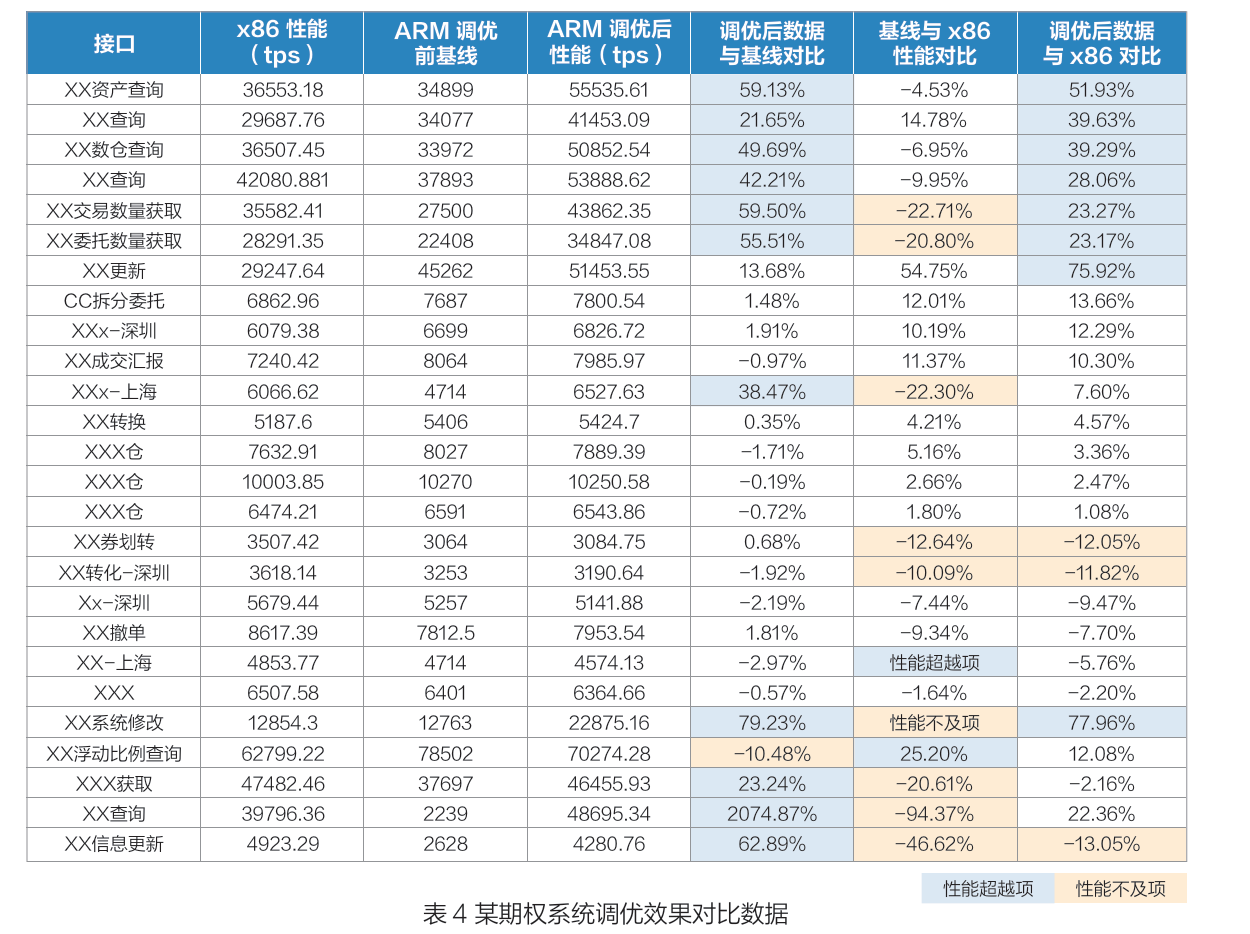
这些数据表明,通过大模型全栈智能调优,国产软硬件的性能潜力可以得到充分释放,有效缩短了信创平台与传统 x86 平台的性能差距,甚至实现了部分场景的性能超越。
四、结语
金融行业的信创自主可控转型是一场关乎国家科技自主可控、金融命脉安全稳定的科技“新长征”,而全栈智能调优则是这场长征中的“最后一战”。大模型技术的崛起,为破解信创转型中的性能瓶颈与职责真空问题提供了革命性方案,通过融合 RAG、模型微调、模型蒸馏、MCP 等前沿技术,构建全流程闭环的智能调优体系,在不增加现有研发运维人员能力栈的前提下,也能够快速充分释放国产软硬件的性能潜力,实现“稳、快、省”的核心目标。
展望未来,随着大模型技术的持续迭代与信创生态的不断完善,信创全栈智能调优将从当前的“自动化”向“智能化、自适应”方向演进,成为公司 IT 核心竞争力的重要组成部分。在这个过程中,AI 必将承担核心引擎角色,通过引入 PD 分离(Prefill 与 Decode 分离),UCM 等 AI 推理加速技术,实现以存代算,显著提升数据处理速度和决策应答响应时效,对于大模型技术在金融智能投研、风控预警、量化决策等领域真正落地至关重要。我们相信,通过行业各方的协同努力,一定能够构建起自主可控、高性能、高可靠的信创核心技术体系,为金融市场的稳定健康发展提供坚实而又自主可控的支撑。
参考文献:
[1] 百度百科 . 检索增强生成 [EB/OL].https://baike.baidu.com/item/%E6%A3%80%E7%B4%A2%E5%A2%9E%E5%BC%BA%E7%94%9F%E6%88%90/64380539,2025 年 2 月 27 日 .
[2] CSDN. 大模型微调技术 [EB/OL].https://blog.csdn.net/chengxuyuanyy/article/details/141320159,2024 年8 月 19 日 .
[3] 知乎 . 一文看懂:MCP( 大模型上下文协议 )[EB/OL].https://zhuanlan.zhihu.com/p/27327515233,2025 年 11月 19 日 .
[4] 知乎 . 贝叶斯优化 [EB/OL].https://zhuanlan.zhihu.com/p/636865469,2025 年 1 月 18 日 .
[5] CSDN. 什么是适配器微调(Adapter tuning)[EB/OL].https://blog.csdn.net/u013172930/article/details/147338877,2025 年 4 月 19 日 .
[6] 百度千帆社区 . 大模型训练——PEFT 与 LORA 介绍 [EB/OL].https://qianfan.cloud.baidu.com/qianfandev/topic/268731,2024 年 3 月 19 日 .
[7] CSDN. 一文彻底搞懂大模型参数高效微调(PEFT)[EB/OL].https://blog.csdn.net/2301_76161259/article/details/142977944,2024 年 10 月 16 日 .
[8] openEuler 官网 .openEuler 智能化解决方案 [EB/OL].https://www.openeuler.openatom.cn/zh/projects/intelligence/,2025 年 4 月 1 日 .
