林旭峰 | 杭州景联文科技有限公司 副总经理
—— 本文收录于《话数 · 第3期》
【摘要】2023 年至今,以大语言模型为代表的生成式 AI 浪潮席卷全球,不仅重塑了人机交互的范式,更引爆了对数字基础设施的深度变革。业界普遍关注“算力”的角逐,然而,一场更为基础且紧迫的“算料”危机——即高质量、海量数据集的短缺正成为制约 AI 大模型持续创新与产业落地的最大瓶颈。正如一句行话所说:“垃圾进,垃圾出”,没有高质量的数据燃料,再强大的算力引擎也无法产出智能的瑰宝。
本文将深入剖析当前 AI 大模型开发所面临的数据挑战,并系统阐述“存力中心+数据精工”联合解决方案。该方案通过构建先进的数据基础设施与全链路数据工程能力,为千行百业破解数据难题,从而真正实现从“数据基建”到“数据价值”的跨越。
一、产业趋势动态:大模型倒逼数据基础设施,数据存力成为新焦点
1. 算力初步就绪,数据存力桎梏凸显
AI 大模型的训练是一个数据密集型和计算密集型的复杂过程。当前产业呈现出一个明显的趋势:算法模型(如 Transformer 架构)在成熟领域的精确度正逐步收敛至 85% 左右,计算成本也在快速下降。这意味着,模型的“智力”天花板越来越依赖于其所“学习”的数据的质量与规模。
然而,现实却十分骨感。大模型开发面临四大核心挑战,其中三项直接指向数据:
1)数据准备时间长:数据来源分散,归集慢,预处理耗时巨大。以某自动驾驶公司的典型场景为例,其需要从分布在全国的测试车辆中归集超过 1 PB 的传感器数据(包含摄像头、激光雷达、毫米波雷达等多种数据源),数据格式不一,且涉及大量非结构化数据。在传统存储架构下,仅数据归集和初步预处理就需要15 天以上,严重拖慢研发节奏。
2)训练集加载效率低:模型参数动辄千亿、万亿级,涉及海量小文件,传统存储加载速度
往往不足 100 MB/s,导致昂贵的 GPU 算力资源大量空闲等待,利用率普遍低于 40%。
3)训练过程易中断:参数频繁调优导致训练平台极不稳定,平均约 2 天就会发生一次中断,需要回溯检查点,造成巨大的时间和资源浪费。
这些挑战的根源,在于传统“存算分离”的架构已无法满足大模型对数据吞吐、并发访问和稳定性的极致要求。数据“存不住”、“流不动”、“用不好”,直接导致了“算料短缺”,成为 AI 产业跃迁的主要“桎梏”。
2. 数据要素市场化催生高质量数据集需求
与此同时,国家政策正大力推动数据要素市场化配置。政府单位、国央企及广大企业不再满足于通用大模型,对构建贴合自身业务的垂类模型需求激增。这催生了对高质量数据集的迫切需求。
这一过程可以概括为:将海量、无序的原始数据,通过专业的加工处理,提炼成结构化数据集,再经过精准的标注成为语料集,最终构建成体系化的知识库。这套“数据精加工”体系,是支撑模型训练和业务应用的基石。然而,公共数据运营等领域同样存在痛点:数据拥有方常因安全、权属与收益分配等问题参与动力不足,而供需双方又存在信息不对称。这亟需一个可信赖的“中间商”角色,来打通数与此同时,国家政策正大力推动数据要素市场化配置。政府单位、国央企及广大企业不再满足于通用大模型,对构建贴合自身业务的垂类模型需求激增。这催生了对高质量数据集的迫切需求。据从资源到资产的“最后一公里”。
综上所述,产业的双重趋势——大模型对数据基础设施的性能要求与数据要素市场对数据质量的要求,共同将“先进存力建设”和“高质量数据工程”推到了舞台中央。
二、用户最佳落地实践:存力中心+全链路数据工程,构建数据价值释放的"双轮驱动"
面对上述挑战与趋势,华为与景联文科技强强联合,提出并实践了以“存力中心”为基石,以“SolarSense 语料工程平台”为引擎的联合解决方案,为行业客户提供了从数据归集、治理到标注、应用的一站式服务,并联合ModelEngine 和 EDS 实现 AI 应用的开发及数据的可信流通,促进数据价值最大发挥。架构的核心优势在于实现了“存算协同”:存力中心确保数据高速流动,SolarSense 平台实现数据精加工,二者协同大幅提升数据处理效率。
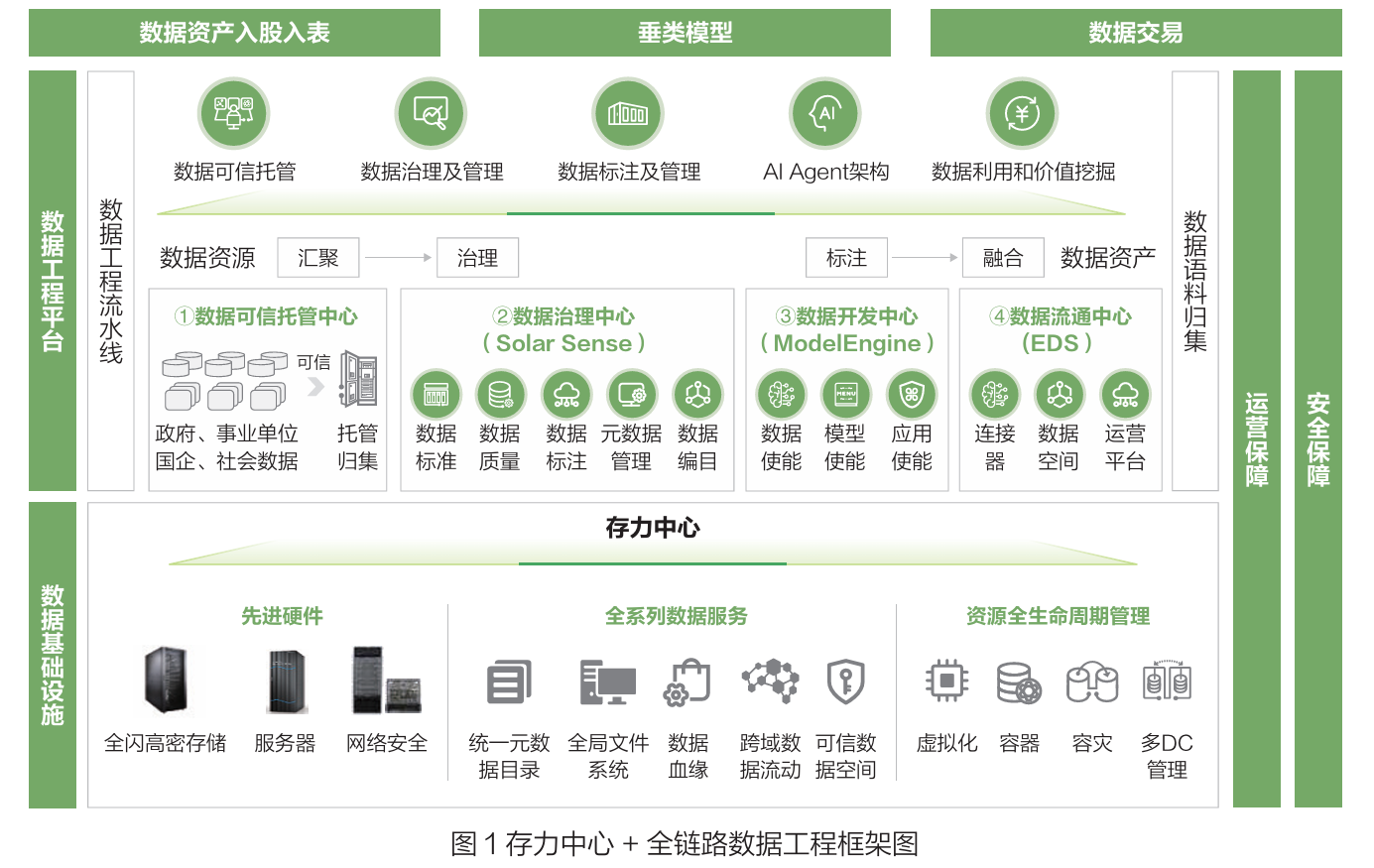
1. 第一驱动轮:筑巢引凤——构建先进存力中心,破解数据存储与流动瓶颈
存力中心,远不止是存储设备的堆砌。根据中国信通院的定义,它是集数据归集、保护、治理、加工与供给于一体的综合平台。本项目携手打造的存力中心,旨在使其成为“数据要素汇聚开发中心、价值中心、产业聚能中心”的集合体。
落地实践案例:某自动驾驶公司数据平台升级:
业务挑战:该公司原有存储系统无法应对日均 100TB+ 的数据增长,训练集加载耗时长达 3 天,GPU 利用率仅 35%。
技术选型:采用华为 OceanStor Pacific系列高端全闪存存储,构建 200PB 规模存力中心。
方案价值:
1)性能突破:通过先进全闪数据湖架构,实现数据加载速度从 100MB/s 提升至 2GB/s,
训练数据准备时间从 15 天缩短至 3 天;
2)成本优化:智能数据分级存储将冷数据自动迁移至对象存储,存储 TCO 降低 30%;
3)稳定性提升:内置数据保护和容灾机制,训练中断频率从 2 天 / 次降低至 15 天/次 。
测试数据显示,GPU 利用率从 35% 提升至 78%,模型训练周期缩短 60%,年节省算力成本超千万元。
2. 第二驱动轮:精工智造——Solar Sense语料工程平台实现AI语料全链路精工智造
SolarSense语料工程平台介绍
SolarSense 语料工程平台是由杭州景联文科技有限公司自主研发的新一代数据生产与治理基础设施,面向多源异构数据的全生命周期管理与运营需求,构建了覆盖数据采集、数据治理、数据标注、质量质检、数据增强与编目运营的“全流程语料工程体系”。平台以“让数据成为可生产、可管理、可运营的核心生产要素”为核心使命,聚焦政务、医疗、教育、金融、具身智能等重点行业在数据资产化过程中普遍存在的数据标准不统一、质量难以量化、治理过程不可追溯、数据价值难以转化等问题,通过工程化、体系化手段实现数据从原始资源向高价值语料资产的系统升级。
SolarSense 平台以“数据生产运营商”理念为指导,将传统以人工为主、分散割裂的数据处理模式,升级为标准统一、流程可控、质量可评、结果可复用的数据生产流水线。平台不仅支持企业和机构内部的数据资产生产与治理,也可作为行业级语料资源运营底座,为政府部门和大型机构提供标准化、可追溯、可计量、可审计的数据资产服务能力。
在功能层面,SolarSense 平台具备以下核心能力:
1)多源异构数据统一接入与治理能力
支持结构化、非结构化及多模态数据的统一接入、存储与索引,实现跨系统、跨类型数据的集中管理与规范治理;
2)语料工程化生产与智能标注能力
通过人工标注、模型预标注与人机协同机制,支持文本、语音、图像、视频等多模态语料的高效生产,满足大模型训练与行业智能应用需求;
3)数据质量控制与评估能力
建立覆盖完整性、一致性、准确性、噪声率等维度的数据质量指标体系,实现数据生产全过程留痕与质量量化评估;
4)语料资产管理与运营能力
对语料数据进行版本化管理、分级分类与价值标识,支撑语料的持续复用、资产化管理与合规流通;
5)安全合规与私有化部署能力
支持可信空间与私有化部署模式,满足政企用户在数据安全、合规审计与数据主权方面的高等级要求。
SolarSense 与存力中心融合互通
SolarSense 语料工程平台与存力中心的融合建设,旨在充分发挥存力中心在数据集中存储、安全管理和长期沉淀方面的基础优势,同时引入语料工程能力,推动数据资源从“可存储”向“可利用、可运营、可增值”转变。通过将 SolarSense 平台作为存力中心的重要应用支撑能力,对存储在存力中心中的多源数据进行统一治理、语料加工和质量评估,在保障数据安全与合规的前提下,持续生产高质量、可复用的语料数据资产。
融合方案重点围绕数据资产化与价值转化目标,打通数据存储、加工、应用与反馈的闭环路径,使存力中心不仅具备数据承载能力,还具备数据价值孵化能力。通过标准化的数据治理和语料生产流程,逐步形成可计量、可追溯、可评估的数据资产体系,为大模型训练、行业智能应用和数据要素流通提供稳定、可信的数据基础支撑,推动存力中心向“数据资源集聚与价值转化平台”升级。
有了高性能的“数据仓库”(存力中心),还需要高效的“数据加工厂”。景联文科技基于华为存储打造的 SolarSense 语料工程平台,正是这样一个专注于 AI 数据集的“精工智造”平台。同时基于 SolarSense 形成的高质量 AI数据集,联合 ModelEngine AI 工具链,可形成从数据到算法开发、模型训练、模型管理、模型推理等能力,支撑将 AI 高质量数据集,通过大模型部署、训练、微调以及应用开发的E2E 工具能力。
通过 SolarSense 和 ModelEngine 的联动配合,提供以下核心能力:
1)以存强算:通过 xPU 池化与高效调度,智算资源可用度提升 30%,KV Cache 缓存推理加速,单卡推理性能 3 倍提升;
2)极简易用:AI 全流程工具链,0 代码开发训练,AI 应用上线周期缩短 80%,软硬件全栈统一管理、智能运维。
SolarSense与存力中心先进存力、一站式AI工具链的融合建设,最终面向用户提供高效、易用的AI全栈方案,支撑大模型与应用一站式开发,实现AI应用快速上线,加速 AI行业化落地。
落地实践案例:某智慧医疗项目数据治理
业务挑战:某三甲医院拥有 10PB 级医疗影像数据,但数据质量参差不齐,标注工作量
大,难以直接用于 AI 训练。
方案实施:通过 Solar Sense 平台的 AI Agent 能力,实现:
1)智能预标注:对 CT、MRI 等影像数据自动识别病灶区域,减少 70% 人工标注工
作量;
2)数据质量治理:自动识别并修复质量问题数据,数据可用率从 40% 提升至 85%;
3)多模态数据融合:实现影像数据与电子病历文本数据的关联分析。
实践效果:平台上线后,医疗数据标注效率提升 3 倍,标注准确率达到 98.5%,成功
支撑医院构建专科疾病诊断大模型。
三、案例启示
深度案例:某大型医院医疗垂域大模型实践
1. 业务挑战
1)数据规模庞大:积累超过 15PB 医疗数据(包含影像、病历、检验报告等);
2)数据质量不一:不同系统数据标准不一致,结构化程度低;
3)标注专业性强:需要资深医师参与,人力成本高且效率低;
4)合规要求严格:涉及患者隐私保护,数据安全管理挑战大。
2. 技术选型与方案设计
医院选择的“先进存力+精工智造”联合方案,其技术架构包含:
1)存力层:华为 OceanStor Pacific 9950全闪存储集群,容量 20 PB,带宽 40 GB/s;
高效数据工程,提供 60%+ 算子、智能标注;
2)平台层:SolarSense 医疗专版,集成医疗数据脱敏、标注、质控模块;多模态模型管理,xPU 池化调度,KV Cache 缓存推理加速;
3)应用层:定制化医疗大模型训练平台,支持多模态数据融合分析;0 代码编排应用开发工具链。
3. 实施效果:
1)效率提升:数据预处理周期从 3 个月缩短至 3 周,标注效率提升 400% ,智算资源
可用度提升 30%,应用上线周期缩短 80%;
2)质量突破:通过 AI 预标注+医师审核模式,标注准确率达成 99.2%;
3)成本优化:人力成本降低 65%,存储TCO 降低 40%;
4)业务价值:支撑的肺结节 AI 诊断模型准确率达成 97.8%,已应用于临床辅助诊断。
四、结语
随着多模态大模型的兴起,对图像、视频、音频等非结构化数据的处理需求将呈指数级增长。“先进存力+精工智造”联合方案,以领先的存力架构和AI驱动的数据工程能力,恰好为应对这一趋势做好了准备。我们相信,“存算并举,数算一体”将是未来数据基础设施的必然形态,而专业的数据服务商将成为释放数据价值的关键催化剂。
在万物互联的智能世界,数据是新的石油,但原油需要经过先进的炼油厂才能变成驱动前行的汽油。我们正是致力于打造这个时代的“数据炼油厂”——以存力中心为坚实的储油罐和输油管,以SolarSense 语料工程平台为智能、高效的炼化装置。我们希望通过这一联合方案,赋能千行百业,帮助它们攻克AI 数据准备的难关,充分释放海量数据的核心价值,共同迎接一个由高质量数据驱动的智能新纪元。
