文 |科大讯飞 徐恩松
一、 应用背景
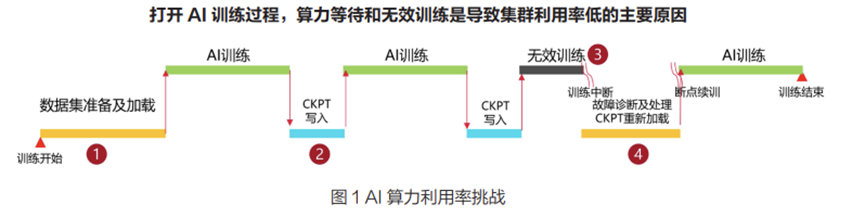
随着ChatGPT在全球大火,大模型成为当下炙手可热的话题。讯飞自2023年5月份首次发布星火大模型以来,大模型能力在不断提升。模型参数越来越大,训练集群规模越来越大,从之前的单机单卡训练转变成多机多卡,甚至万卡集群的训练。因此存储读写性能直接影响了计算集群的可用度。并且随着训练集群规模扩大,集群故障频率增高进一步加剧了计算集群可用度降低,业界GPU算力用于有效训练的时间不超过50%。存储读写性能对计算集群可用度影响如下图所示。
讯飞HPC训练平台从2015年开始建设,经过8年发展,存储方案经过三次大的迭代演进,目前在向第四代架构探索。

第一代存储架构采用传统磁盘阵列方案,该方案在数据增长之后,扩容存在严重的瓶颈。
第二代存储架构采用开源分布式存储软件,在使用过程中,我们在性能和稳定性方面均遇到了较多的挑战,因为投入有限,短期内很难攻克解决。随后又转向第三代架构演进。
第三代存储架构采用标准的商业分布式存储方案,基本解决了性能及稳定性方面问题,但是在数据治理方面没有有效的手段,无法在海量数据规模中快速检索出低频访问数据、数据无法进行分层流转,导致资源成本越来越高。
当数据规模增长到一定规模后,我们对于存储的要求会越来越高,性能、可靠性是基础,在此之上,我们更需要探索出一套有效的数据全生命周期管理方案。
二、 面临的挑战
大模型,让人工智能技术逐步从感知理解世界向生成创造世界进行跨越式演进,可以说数据质量决定了AI智能的高度。要提升模型质量,我们目前面临以下多个数据管理与处理问题:
1.数据治理困难:AI训练集的文件数量有百亿个,当前“烟囱式”存储集群的建设模式,形成多个数据孤岛,数据需要人工迁移,效率低。同时无全局数据可视能力,无法识别冷热数据与高价值数据,数据难以治理。
2.GPU利用率低:AI大模型训练以多机多卡任务为主,故障频率高,模型加载和断点续训CheckPoint读写时,对存储系统IO和带宽性能要求很高,千卡以上集群平均每天故障1次,断点恢复时间高达15分钟+,每次损失几十万。
3.集群分散不可靠:多套存储“烟囱式”建设,总容量几十PB,切分成几十个PB级的分散小集群,极大地增加了管理复杂度,并采用软硬分离的方式建设存储集群,降低了存储集群的可靠性同时也降低了带宽能力。
4.多元化的数据接入问题,异构存储管理复杂。
5.样本集越来越大的问题,从TB级增加到PB级,原始数据甚至可能达到EB级。
6.训练参数越来越大的问题,模型训练中,目标模型参数能达到千亿级甚至万亿级。
7.数据安全性问题:在整个训练和数据使用过程中,一旦出现数据丢失或数据安全合规问题,对模型训练的质量和效率都是致命的。
三、建设方案
目前,讯飞与华为强强联合,打造最佳大模型算力+存力全栈方案。我们基于昇腾AI基础软硬件,包括Atlas系列AI芯片和服务器、昇思全场景AI框架、CANN异构计算框架,打造讯飞火石平台,支撑讯飞星火大模型训练和推理。我们也基于华为OceanStor分布式存储,打造统一存力底座,并且正在开展多项研究,包括:
1.算力、存力协同体系研究,目标训练效率提升10%~20%;
2.数据价值精准识别与治理,提升不同价值数据的流转联动效率;
3.基于场景的数据缩减技术探索,实现数据全生命周期管理和存储成本降低。
讯飞一直致力于打造一个面向未来的、高效的、可靠的大模型数据基础设施。我们认为,国产大模型只有基于自主创新的算力和存力底座才有大未来。下面具体介绍一下方案的一些细节内容。首先我们采用的是存储分离的架构。如下图:
在计算与调度层,我们构建了支持多样化异构算力的平台,其中就包含了最新一代华为昇腾AI算力,建成了算力集中、性能优越、供给稳定和安全的大模型训练算力集群;
在数据存储层,我们首次应用统一存储平台的理念,基于OceanStor分布式存储,我们建设了一套融合的存力体系,这套体系主要能我们解决以下四个关键问题:

一是解决了多种来源、多种类型数据免迁移快速归集;对外提供多种协议,让数据存进来。不需要在各个存储集群之间互相拷贝迁移,大大节约了数据预处理时间和成本。二是提供了面向不同I/O模型的自适应处理机制,解决了多场景作业训练对于存储性能要求。
三是免人工干预的数据热度识别,通过策略配置,对海量数据进行自动分层,既满足了海量原始数据的存储需求,也提供了高性能模型训练的能力;最后,新一代创新体系从基础设施的自主安全、全流程的数据高可用保障,以及服务等级、数据使用权限管理和外因数据安全威胁方面提供了灵活可选择的方案,为我们的模型训练提供了强有力的保障和支撑。
GPU在AI大模型IT基础设施的价值占比最高,约50%左右,甚至更高。提升GPU利用率就意味着经费的节省。特别是在模型Checkpoint的加载和恢复期间,往往意味着小时级甚至天级的等待时间。那么如何才能将存储的性能发挥到极致,使存储不再成为训练中的瓶颈?主要有以下2个方案:
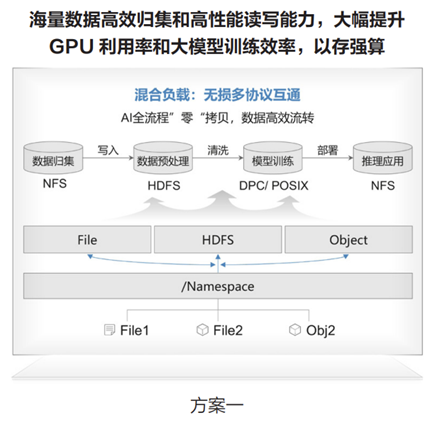
首先,分布式存储的多协议无损互通能力,能够让AI大模型数据从收集、预处理、训练/推理全流程零拷贝,一套存储就可以实现多种来源、多种类型数据免迁移快速归集和高效读写,上一环节的数据能够快速作为下一环节的输入。这样做的好处主要有2个:1个是减少了数据重复拷贝的时间,再一个就是避免了大量数据重复存储的问题,也一定程度上节省了存储的成本。
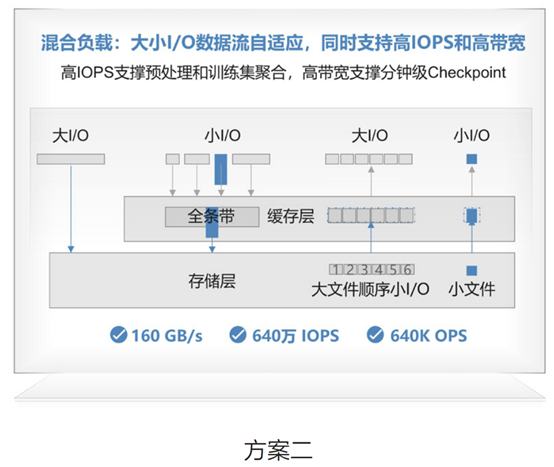
第2个方案就是分布式存储能够针对大小I/O采用不同的处理机制,这个机制是存储侧自动进行识别,如果是大IO从客户端写入,则直通到机械盘,减少路径开销;如果是小IO写入,则在缓存层聚合后再下盘,大幅降低I/O交互次数,提升IOPS性能。实现了一套存储同时支持高IOPS和高带宽的能力。
现在AI大模型已进化到接近EB级的数据量、同时一个训练集群上也会有多个任务并行训练。如果一些用户的训练任务参数配置不合理,过多消耗存储IO,很容易产生性能抢占,影响其他任务的训练效率。我们跟华为数据存储团队协同,创新性地在同一套存储系统中,按需构建多个物理隔离的存储池。同时实现一个客户端可连接多个存储池。这样,每个大模型数据都有自己专属保障性能/容量的存储池,实现了文件系统级的物理隔离,降低了性能抢占的影响范围,同时也将故障域缩小了。当然,多个存储池之间是采用同一套存储系统,管理也很简单、维护起来也很方便。

四、实用性分析
断点续训恢复速度提升15倍:集群最大提供TB级大带宽,缩短CheckPoint读写耗时,断点续训恢复时长从15min缩短到1min,日节省几十万元人民币。
存储集群安全可靠:AI存储单集群多StoragePool的方案,管理面合一,数据面分离,通过数据面隔离避免AI集群故障扩散;同时通过亚健康管理,大比例EC等进一步提升存储可靠性,单集群可靠性达5个9。
全生命周期管理TCO降低30%:统一数据湖管理,GFS全局文件系统,无损多协议互通,免除数据孤岛,数据全局可视、可管,高效流动,跨域调度效率提升3倍,数据零拷贝,端到端加速AI模型开发;千亿元数据秒级检索,智能识别数据热度,精准分级,实现存储系统性能与容量均衡。
五、效益与价值

讯飞深耕教育赛道多年,自首次发布讯飞星火大模型以来,就将该技术应用到教育场景。讯飞畅言智慧课堂产品就是一个成功的例子。多模态能力在教育领域的应用是很成功的。基于讯飞星火2.0版本多模态能力,如图像描述、理解、推理以及识图创作,文图生成、虚拟人合成等,可以从真实世界获得越来越多的数据,并在产品终端进行学习、训练和提升,有效助力课堂创新,大幅降低课堂内容的制作周期和内容制作成本。

