
Ensong Xu | iFLYTEK Senior Storage Solution Architect
I. Background
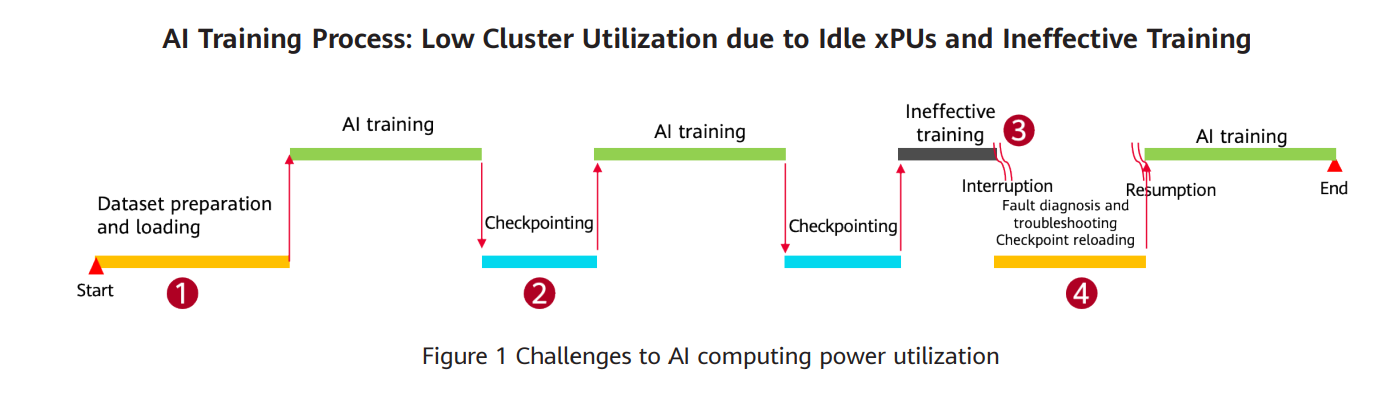
The rise of ChatGPT has thrown large AI models into the spotlight. Take iFLYTEK for example, which has been improving its Spark Model since its first release in May 2023. Owning to increasing parameters, the training cluster has grown from single-node, single-xPU training to using multiple nodes and xPUs, even over 10,000 xPUs. The storage read/write performance directly affects utilization of the compute cluster. The larger the training cluster and the higher the frequency of cluster faults, the greater the risk of reduced cluster utilization. Typically, GPU utilization for effective training is less than 50%. The following figure shows the impact of storage read/write performance on compute cluster utilization.
iFLYTEK started constructing its HPC training platform in 2015. In the following eight years, the storage architecture that goes with the platform has been updated three times with the fourth generation being developed.

The first-generation storage architecture adopted a conventional disk array, which failed to scale with the growing data.
The second generation utilized an open-source distributed storage software, which encountered performance and stability challenges that were too time-consuming to solve.
The third generation implemented a standard commercial scale-out storage solution. Although this solution solved the aforementioned performance and stability issues, it failed to support efficient data governance. It was slow to retrieve less frequently accessed data from massive amounts of data records; tiered data transfer was also unavailable. This had led to frustratingly increasing resource costs.
As the data volume reached a certain level, the storage requirements expanded from being high-performance and reliable to also providing an efficient, full-lifecycle data management solution.
II. Challenges
Along with the development of large AI models, AI technology has advanced from focusing on perceiving and understanding the world, to a more widespread focus on generating and creating it. The quality of data determines how far AI can evolve. To improve model quality, we need to address the following issues regarding data management and processing.
1. Difficult data governance: The training dataset of a large AI model consists of tens of billions of files, which are usually stored in separate clusters, causing data silos and inefficient manual migration. To further complicate this, a lack of global data visualization resulted in failure to identify hot and cold data and high-value data, hindering data governance.
2. Low GPU utilization: Training of large AI models mainly involves multi-node and multi-xPU training jobs, which have high fault rates. High-performance storage I/O and bandwidth are needed for checkpoint reads and writes during model loading and training resumption. For example, a training cluster with thousands of cards experiences a fault about once a day and takes 15+ minutes to resume training, leading to a loss of hundreds of thousands of Chinese Yuan for every fault.
3. Separate and unreliable clusters: iFLYTEK's live network used to consist of multiple siloed storage systems. They provided a total storage capacity of dozens of petabytes in the form of separate PB-level clusters, leading to highly complex management. In addition, software- and hardware-independent deployment reduces the reliability and bandwidth of storage clusters.
4. Diversified data access: Accessing diverse data from heterogeneous storage systems complicates storage management.
5. Rising data quantity: Sample datasets have grown from terabytes to petabytes, and raw data may even reach exabytes.
6. Growing training parameters: Sometimes a target model contains hundreds of billions or even trillions of parameters for training.
7. Data resilience challenges: Data loss, security breaches, or compliance issues during model training and data usage can severely impact training quality and efficiency.
III. Construction Solution
iFLYTEK has worked with Huawei to create a full-stack computing and storage solution for large AI model training. iFLYTEK's Huoshi platform is intended to support training and inference of the Spark Model. At its heart lies Ascend AI, a hardware and software infrastructure consisting of Atlas series AI chips and servers, the versatile-scenario AI framework MindSpore, and the heterogeneous computing architecture CANN. iFLYTEK has also built a unified storage foundation using Huawei OceanStor scale-out storage to support various researches, including
1. Research on compute-storage collaboration, aiming at improving model training efficiency by 10% to 20%
2. Precision identification and governance of data value to streamline data transfer and coordination
3. Scenario-specific data reduction to implement full-lifecycle data management and reduce storage costs
iFLYTEK has been committed to building a future-oriented, efficient, and reliable data infrastructure for large AI models. To develop a thriving large AI model, we need to innovate in computing power and storage. Our solution, shown below, decouples storage and compute.
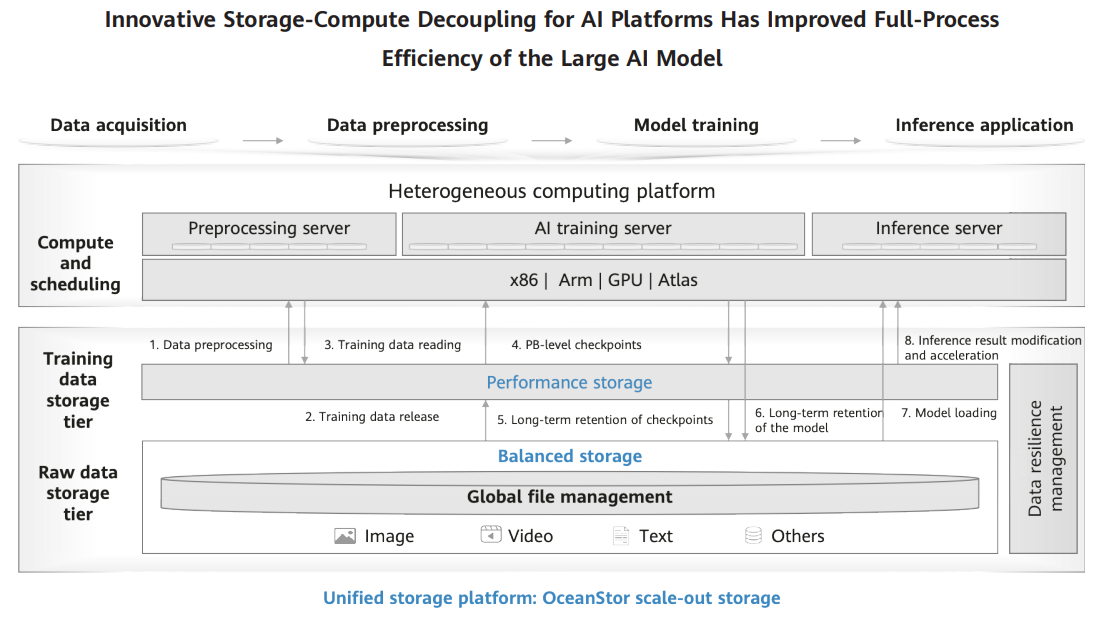
At the compute and scheduling layer, a platform is set to support multi-architecture computing, including the latest generation of Huawei Ascend AI computing power. This platform provides a centralized computing cluster for model training, delivering superior performance, stability, and resilience.
At the data storage layer, we first applied the concept of a unified storage platform and built a converged storage system using OceanStor scale-out storage. This system has provided the following benefits.

1. It quickly collects multiple types of data from various sources without migration and supports multi-protocol access for data storage. This eliminates the need for data copying between storage clusters and significantly reduces time and cost spent on data preprocessing.
2. The system provides a processing mechanism that adapts to different I/O models, meeting the performance requirements for model training across multi-scenario jobs.
3. Automatic identification of data access frequency is implemented. Additionally, through policy configuration, the system can automatically tier mass data. This fulfills the storage needs of mass raw data and helps enhance model training performance.
4. This innovative system provides flexible solution choices regarding infrastructure resilience, end-to-end high data availability, service level, data use permission management, and prevention against external risks. In this way, it delivers robust resilience for model training.
GPUs make up the largest portion of the IT infrastructure value for a large AI model, accounting for approximately 50% or more. Improving GPU utilization means saving costs. During the model training process, checkpoint reloading and training resumption often take hours, even days, during which time GPUs are idling, particularly impacting their utilization. Maximizing storage performance can help tackle this issue. We adopted two solutions to maximize the strength of scale-out storage.
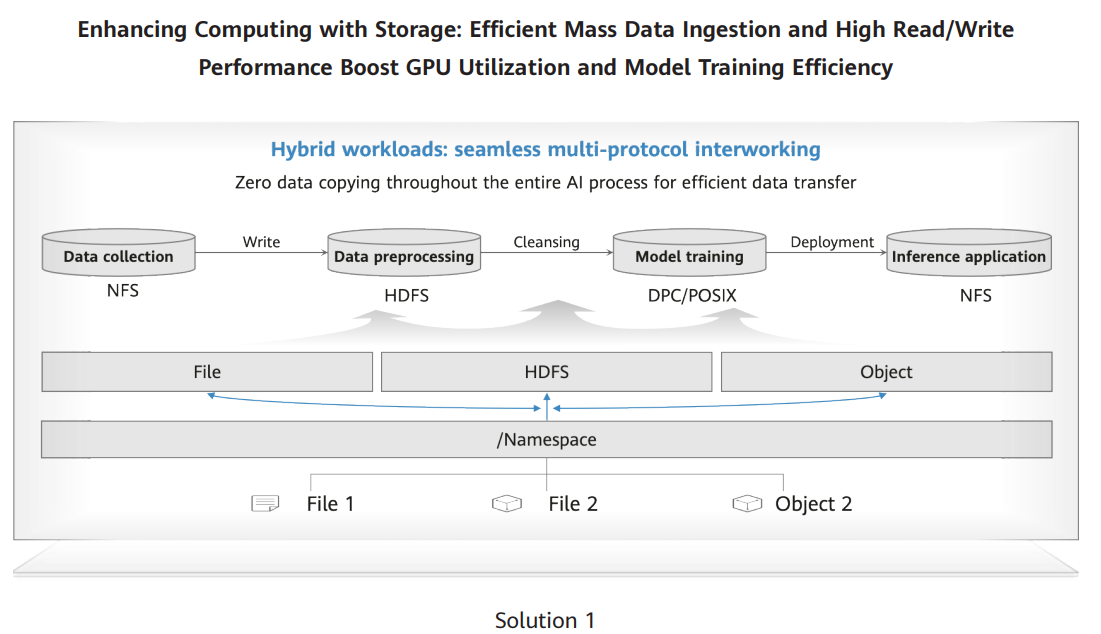
The first solution features seamless multi-protocol interworking capability, which eliminates the need for data copying throughout the full process of data collection, preprocessing, and training/inference. One storage system supports quick collection and efficient read/write of diverse data from multiple sources, allowing the output data of a training phase to be quickly used as input of the next phase. This solution reduces the time spent on data copying and eliminates data duplication, improving cost-effectiveness of storage.
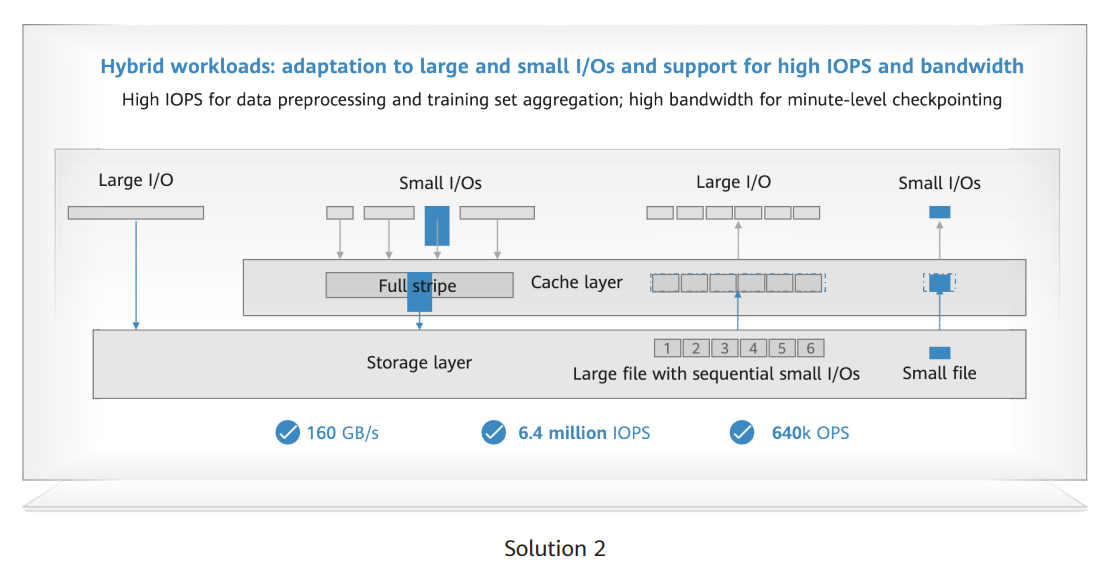
With the second solution, the storage system automatically identifies large and small I/Os and adapts data flows accordingly. Large I/Os are passed through from clients to disks, reducing path overheads, while small I/Os are aggregated at the cache layer and then written to disks, greatly decreasing the number of I/O interactions for higher IOPS performance. In this way, one storage system can meet both high bandwidth and high IOPS requirements.
The data for a large AI model is reaching the scale of an exabyte. Meanwhile, there can be multiple training tasks parallelly running in one cluster, competing for resources. A training task with poorly configured parameters can overly consume storage I/O resources and cause performance preemption, affecting the efficiency of other training tasks. We worked with Huawei Data Storage team to innovatively create multiple physically isolated storage pools to meet the needs of different training tasks. Additionally, one client can connect to several storage pools. In this way, each model is provided with a dedicated storage pool to ensure performance and capacity. Further, physical isolation at the file system level reduces the scope of impact in the event of performance preemption and also narrows down the fault domain. All these storage pools are based on the same storage system, simplifying management and maintenance.
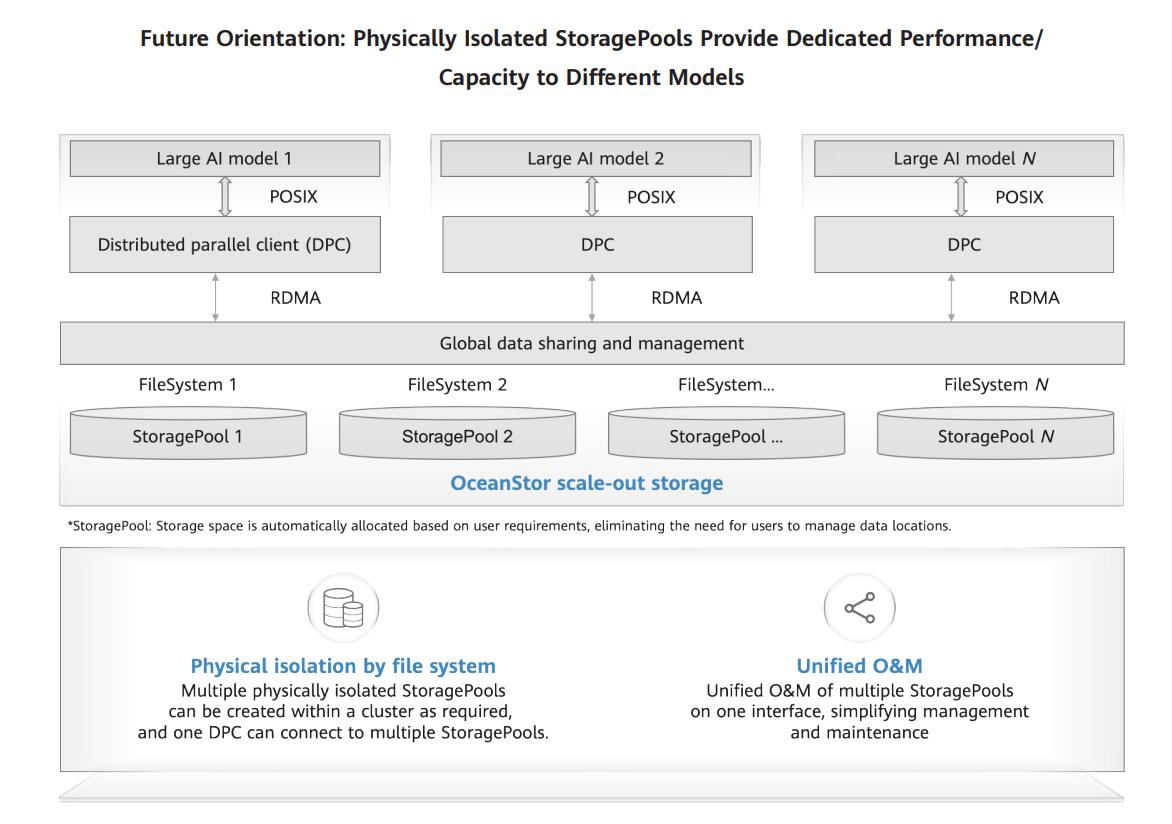
IV. Practicability Analysis
15-times faster training resumption: The training cluster provides up to TB-level bandwidth for faster checkpoint reads and writes. This accelerates training resumption from 15 minutes to one minute, leading to significant monetary savings.
Resilient and reliable storage clusters: AI storage supports unified management of multiple storage pools in a single cluster. At the same time, separation of data planes prevents a fault in any storage pool from affecting other storage pools in the cluster. In addition, the reliability of a single cluster can reach 99.999% due to storage reliability functions such as subhealth management and high-ratio EC.
30% lower TCO thanks to full-lifecycle management: Unified data lake management is achieved using the global file system (GFS) and seamless multi-protocol interworking, thereby eliminating data silos. Global data visualization and management enable efficient data flow, 3-times more efficient cross-region scheduling, and zero data copying, accelerating all stages of AI model development. Hundreds of billions of metadata can be searched in seconds, and intelligent identification of data access frequency enables precise data tiering, properly balancing storage performance and capacity.
V. Solution Benefits
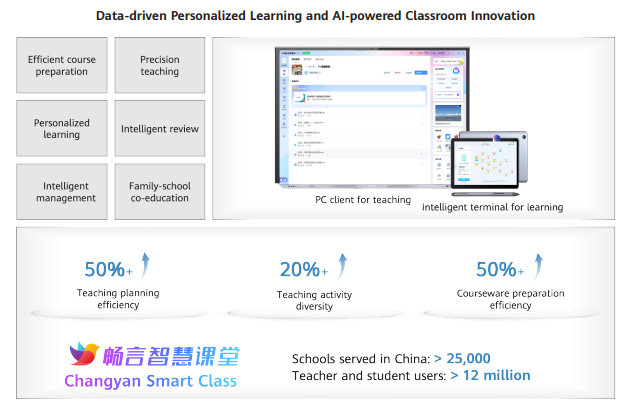
iFLYTEK boasts years of experience in the education industry and has extensively applied its Spark Model in education environments. Multimodal applications have proved successful in this industry, and iFLYTEK's Changyan Smart Class is a prime example. It utilizes multimodal capabilities of the Spark Model 2.0, including image description, understanding, and inference, as well as image-based creation, image-text generation, and virtual human synthesis. This application feeds real-world data to the model, which learns, trains, and fine-tunes itself at the application terminal. In this way, the application helps innovate classrooms and streamlines course preparation.
Source: Data Dialogue (2025 Jan. issue)

