Yulan Zhang | Data Operations Expert, Digital Intelligence Center, China Automotive Engineering Research Institute Co., Ltd.
— Included in Data Dialogue, Issue 002
Intelligent vehicle sensing systems are evolving into multimodal systems. The rapid growth of heterogeneous data like videos, point clouds, and vehicle buses is creating serious storage challenges. This article analyzes three major bottlenecks in storage power: data, application, and management. It explores the trade-offs between training efficiency and costs in mainstream solutions like object storage and acceleration layer, parallel file systems, and converged architecture and proposes design directions for future-proof data platforms that enable algorithm iteration and intelligent applications.
I. Status Quo and Challenges
Intelligent driving R&D, characterized by high business value, generates massive amounts of data over the course of data collection, labeling, training, and simulation. Different phases of the data lifecycle have distinct storage requirements. This article analyzes the storage challenges in terms of data, application, and management.
1. Data challenges
(1) Small file storms and metadata bottlenecks
In autonomous driving data processing, long videos are split into millions of image frames, generating mass small files. Training requires frequent access to these small files, which creates significant metadata challenges that cannot be addressed by traditional standalone file systems. Conventional HDFS deployments with coupled storage and compute also struggle to scale metadata performance linearly. Metadata processing emerges as a major bottleneck for the concurrent reading of small files.
(2) Imbalance between hot and cold data and storage costs
In intelligent vehicle data management, only a small fraction of data—mostly recent key applications and corner cases—is frequently accessed as hot data. The overwhelming majority of data ages into cold data that needs to be retained indefinitely despite being rarely accessed. Storing all of the data on high-performance media becomes prohibitively costly as the scale increases. However, storing cold data on low-performance storage media results in high access latency. It is critical to automate the identification of hot and cold data for seamless tiering, which helps balance performance and cost.
2. Application challenges
(1) Data silos and migration across different phases
The data pipelines for autonomous driving R&D span data collection, cleansing, training, and simulation. Conventionally, each of these phases was conducted on a separate storage system. Data is frequently shuttled between phases through scripts for exporting, format conversion, and re importing. This creates cumbersome workflows, massive data redundancy, and entrenched data silos. Storing redundant copies at each phase not only creates massive storage waste, but significant synchronization challenges. This fragmented approach constrains the flow of data in the algorithmic closed loop, hindering R&D efficiency.
(2) Limited computing power and training delays
GPUs are the most expensive computing resources in model training and simulation. Traditional standalone file systems and centralized storage architectures are constrained by the I/O throughput and metadata processing capabilities of individual nodes on the storage side, which frequently results in under 50% GPU utilization. These systems cannot support training workloads for high-concurrency access. During random reads of small files, individual storage nodes and centralized metadata service become performance bottlenecks that prevent a continuous data stream to a large number of GPU compute nodes, causing frequent I/O waits, idle GPUs, and blocked or failed training tasks. Training efficiency is bottlenecked by storage performance rather than computing power. To unleash the potential of AI computing, it is essential to enhance the concurrent access and metadata service capabilities of storage systems for efficient collaboration between storage and GPU compute nodes.
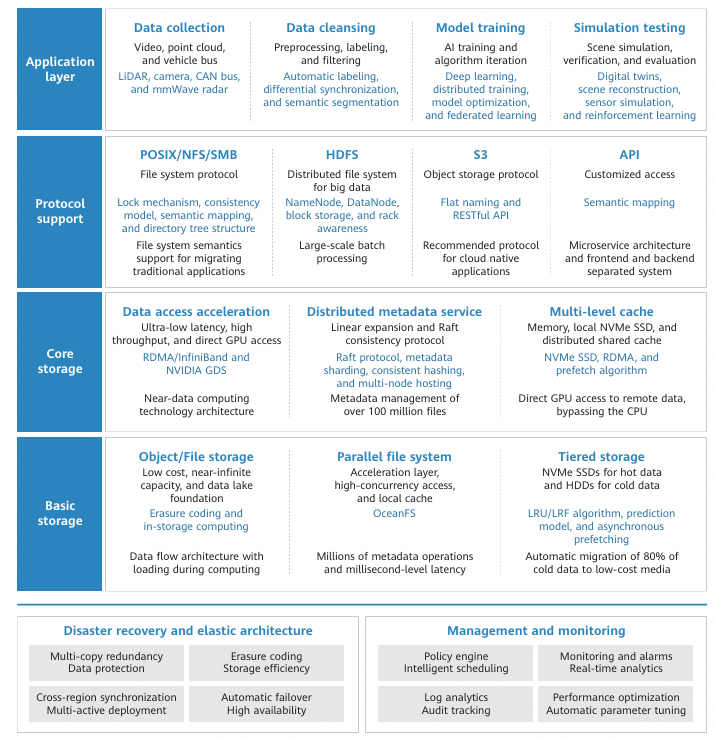 Figure 1 Intelligent vehicle data storage architecture
Figure 1 Intelligent vehicle data storage architecture
3. Management challenges
(1) Complexity in cluster elasticity and scalability
The scale of autonomous driving data often reaches the PB-level. During peak training periods, tens of thousands of nodes require concurrent access.
However, during off-peak periods, resources are largely idle. This means the storage system needs to support both high concurrency and elastic scaling. Traditional standalone file systems and distributed storage systems often face issues like client mounting failures and delayed metadata synchronization. Moreover, after the expansion of nodes and disks, the absence of load balancing and self-healing mechanisms can create large O&M workloads. Therefore, the scalability and ease of O&M of the architecture have become key considerations.
(2) Data resilience and reliability
Massive amounts of road test data are the foundation of autonomous driving R&D. Any loss of data can be costly. Traditional backup solutions are ill-equipped to handle PB-level data. These architectures typically rely on multi-copy redundancy and cross-region disaster recovery (DR). Multi cluster deployment requires a complex consistency assurance mechanism. A single cluster fault can disrupt the entire process if there is a flaw in the DR design. Automatic DR and copy synchronization need to be implemented at scale to ensure 24/7 platform stability, which remains critical management challenge.
In conclusion, the intelligent vehicle data is characterized by high volume, significant cold and hot data disparities, long pipelines that are prone to silos, and large and dynamic system scales. The storage architecture must address the three major challenges in management, application, and O&M to build a solid data foundation for autonomous driving R&D.
II. Storage Architecture Design and Optimization
To overcome the aforementioned bottlenecks, this article proposes an intelligent vehicle data storage architecture that covers the entire pipeline from data collection to training. This architecture uses parallel file systems and object storage to connect the preprocessing phases to GPU clusters. It balances performance and costs through distributed metadata optimization, small file processing, multi-level caching, tiered storage, multi-protocol support, and cross-region DR.
1. Distributed metadata services and small file I/O optimization
Autonomous driving training data primarily consists of small files, such as video frames, point cloud slices, and annotation files. In high concurrency access scenarios, metadata operations like directory traversal, inode lookups, and permission verification are the main bottlenecks constraining storage I/O throughput and GPU utilization. Parallel file systems and distributed metadata services in the training acceleration layer can address the metadata scalability issue of concurrent access to large numbers of files. Metadata is sharded by directory or namespace, with requests distributed across different nodes for processing. This allows metadata processing performance to scale linearly while remaining decoupled from the data path. For applications requiring concurrent training and access to over 100 million files, the frequency of metadata access can be significantly reduced by combining mechanisms for small file aggregation, metadata caching, and batch prefetching. This ensures a continuous data supply for GPU training and effectively mitigates the issue of compute being bottlenecked by storage.
2. Data lake architecture with decoupled storage and compute
The architecture decouples storage from compute to enable mass data storage and elastic compute through independent scaling. A data lake is built on object storage to deliver low-cost, near-infinite capacity for explosive growth of autonomous driving data and frequent model iteration. However, due to high latency and lack of file semantics, object storage alone is insufficient for training. A parallel file system needs to be used as an acceleration layer on top of the object storage to provide Portable Operating System Interface (POSIX) semantics, high-concurrency access, and local caching. For typical industry applications, this approach can reduce the access latency of small files by 50% to 80%, double or triple the random read/write throughput, and shorten the pre-training data processing time by over 30%. Similar architectures have been used and validated in autonomous driving data lakes by leading automotive enterprises.
3. Multi-level cache and data access acceleration
To reduce the access latency caused by remote object storage, the architecture uses a multi level cache system to accelerate the data path. L1 caching leverages high-speed local caches like NVMe SSDs or memory on compute nodes to cache hot data and metadata. This improves the cache hit rate and reduces redundant I/Os. For autonomous driving training, local SSD caching can significantly improve throughput performance.
In L2, a distributed shared cache is deployed on the storage cluster, allowing nodes to share the loaded data. This prevents redundant data fetches from the object storage, enhances multi node training efficiency, and reduces network pressure. The cache service runs independently of training nodes to maintain cache availability. Data persists even if containers are scaled frequently, which ensures a stable cache hit rate. The local cache + cluster cache + high-speed network design provides multi-level acceleration for higher training performance without indiscriminate scaling of hardware resources. This balances performance and cost.
4. Tiered storage and management of hot and cold data
The architecture's tiered storage strategy also helps balance performance and cost. Hot data is stored on high-speed storage media like NVMe SSDs and parallel file systems, while cold data is automatically moved to low-cost storage media like large-capacity HDDs. The system provides real-time visibility into data access patterns using a policy engine and identifies hot and cold data using predictive models and policies like Least Recently Used (LRU) and Least Frequently Used (LFU). Identified data is automatically migrated and asynchronously prefetched in the background without affecting training performance. This tiered data storage management mechanism increases performance for hot data and lowers costs for cold data, enabling efficient management of multimodal data in the petabytes. A number of automakers have already applied this approach to autonomous driving model training and simulation data management. Automatically tiering hot and cold data significantly reduces high-performance storage loads, more than doubles the cache hit rate, and reduces data loading time during training by at least 20%.
5. Multi-protocol support and unified data platform
Autonomous driving model training entails the phases of road test data collection, offline data cleansing and feature processing, GPU cluster training, and result archiving. Each phase has distinct data access patterns and performance requirements. The architecture provides a unified, multi-protocol data platform that prevents unnecessary data migration and redundant copies caused by fragmented systems. Access protocols such as POSIX, HDFS, and S3 are supported under a single namespace to ensure semantic consistency and interworking with no performance impact. In the road test data collection phase, the POSIX interface is used to support concurrent multi-source writes and low-latency disk flushing. In the data cleansing phase, the HDFS interface is used to adapt to large-scale sequential reads and writes and computing frameworks. In the model training phase, the POSIX interface is used to load the cleaned data directly so as to meet the throughput and random access needs of GPU training. The training results and intermediate products are all archived through the S3 interface. Adapting protocols to each phase enables seamless data flow across collection, cleansing, and training without migration or copying, which significantly increases overall data processing and computing efficiency.
6. Elastic architecture and automatic DR
For cluster management, the architecture provides a shared-nothing distributed architecture in which all storage nodes are symmetric and elastic scaling is supported. Nodes can be temporarily added to increase concurrency during peak hours, and resources can be released during off peak hours. This ensures a dynamic balance between performance and cost. New nodes can be seamlessly added, enabling linear increases in capacity and throughput to handle variable workloads. To ensure data resilience, the system provides built-in multi-copy redundancy and self healing mechanisms. Data is distributed and stored using multiple copies or erasure coding. In the event of a node failure, other nodes automatically take over its duties and data is automatically restored using copies. In addition, the system rebalances data in the background to complete fault recovery with minimal manual intervention. Multi-active deployment across data centers is supported for more advanced DR.
Metadata and object data are synchronized across remote clusters, or object storage is mapped to local systems to form collaborative DR capabilities. Even if a node or equipment room is faulty, services can be recovered quickly without interruption, ensuring 24/7 support for R&D tasks. The elastic scaling and DR architecture design provides a strong foundation for data-intensive applications like intelligent vehicles.
III. Conclusion
The multimodal data storage architecture has proven to be effective for autonomous driving training. Tiered storage, multi-level caching, and multi-protocol convergence significantly alleviate the small file access bottleneck, improve training throughput, reduce overall costs, and enable efficient transfer of petabytes of data. As intelligent vehicle data continues to grow, architecture optimization will need to focus on smarter hot and cold data management, more efficient cross-protocol access, and efficient collaboration and elastic scaling. This will further improve multimodal data processing efficiency and ensure sufficient compute and storage resources for large-scale autonomous driving R&D.
Access Data Dialogue, Issue 002 →

