【摘要】本文以DeepSeek一体机为研究对象,从部署步骤、工具链支持、模型兼容性等维度,对比分析了X86平台(Intel+NVIDIA)与昇腾平台(Kunpeng+Ascend)两种主流软硬件生态下的实际使用体验,具体涉及开源工具链(Ollama、Docker、NVIDIA Container/CUDA、Dify)以及ModelEngine工具链的表现差异。
随着AI大模型在企业、科研和行业应用中的普及,及其本地化部署需求的迅速增长,特别是在“推理+微调”场景中,因涉及数据合规性、延迟优化、网络稳定性及成本可控性等因素,越来越多的组织选择将大模型从云端迁移到本地算力平台中运行。在这一背景下,DeepSeek一体机作为一款融合软硬件于一体的本地部署解决方案,正在多个应用场景中获得实际落地。例如,企业内部问答系统、医院自动化生成病历、政企数据智能平台、AI辅助决策系统等。这些使用场景往往对响应时间、稳定性、数据不出域、可控成本等方面提出了更高要求,使得“一体化推理部署”成为趋势。
实际部署过程中,不同CPU/GPU组合会对流程产生显著影响。本文从部署步骤、工具链支持、模型兼容性几个层面,横向观察DeepSeek一体机在不同软硬件生态下(Intel+NVIDIA(下文简称X86平台)与Kunpeng+Ascend(下文简称昇腾平台))的使用体验对比。同时对比了当前较主流的开源工具链(Ollama、Docker、NVIDIA Container、NVIDIA CUDA、Dify)与华为ModelEngine工具的表现。
一、部署环境划分与评估维度
1、测试环境说明
本次测试均采用单节点部署方式搭建DeepSeek推理一体机,从而真实地还原典型应用场景下的运行状态。为确保测试结果在不同平台间具备高度的相关性与可比性,我们在配置选型上尽可能保持X86平台与昇腾平台一体机的软硬件规格相近。
(1)硬件服务器配置
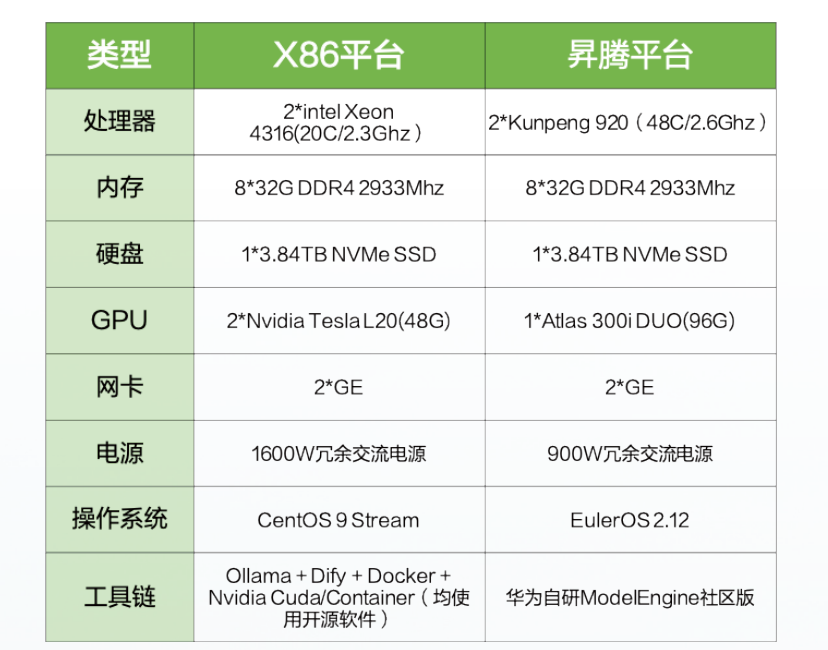
(2)平台部署架构
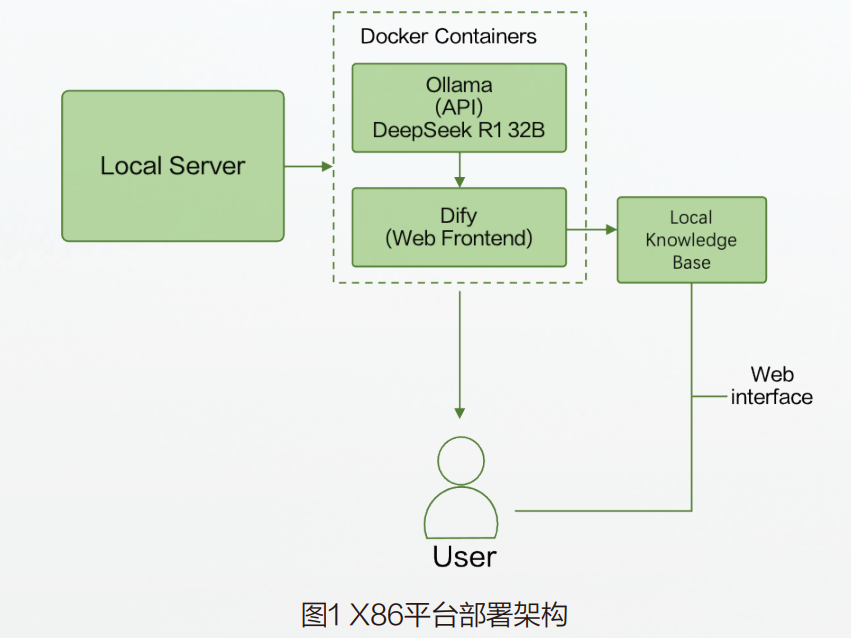
两套方案均引入Docker技术,以容器化的方式承载大模型与配套工具链,不仅提高了部署的灵活性与环境的一致性,也为后续的扩展与复现提供了坚实基础。
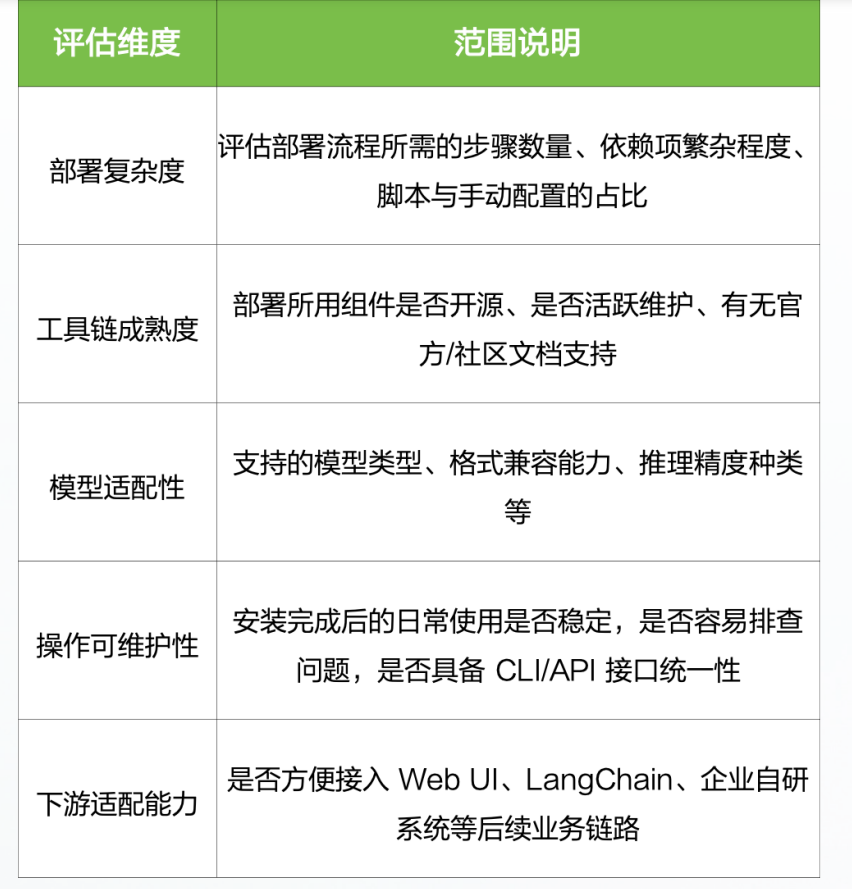
2、评估维度设计
为保证对不同方案的横向分析具备一致性与操作性,将从部署步骤、工具链支持、模型兼容性等五个维度进行统一评估,评估维度和范围说明如下表:
二、部署流程与工具链拆解对比
不同软硬件平台在实际部署DeepSeek模型时,会因操作系统、驱动体系、依赖环境和工具链兼容性等方面的差异而产生完全不同的部署体验。以下将从两个主流平台出发,逐步拆解其部署步骤,并对关键组件、模型加载方式、工具链结构等进行横向对比。
1、部署路径

2、部署步骤
(1)X86平台部署步骤
►安装GPU驱动
- 安装匹配显卡型号的官方NVIDIA驱动(如L20使用535+)。
►配置NVIDIA-docker支持
►运行Ollama容器
►加载DeepSeek模:DeepSeek-r1:32b。
►配置Dify和Ollama内容的模型对接
- 登陆,单击用户名→「设置」→「模型供应商」→「Ollama」;
- 添加自定义本地Ollama模型,基本信息:模型供应商OpenAI,模型名称DeepSeek-r1:32b;
- Dify控制台首页「创建应用」→DeepSeek问答机器人;
- 使用知识库能力新建知识库,上传文档;
- 测试对话。
(2)昇腾平台部署步骤
►安装检查
- 录到OS内,切换到root,检测NPU状态是否正常。
►录入软件包
- 华为support官网下载;·新建目录解压安装包。
►部署ModelEngine软件
- 部署OMS服务并安装自动脚本(~15min);
- 查看POD状态。
►部署数据使能
- 部署数据使能脚本(~30min);
- 查看POD状态;
- 获取MetaVision的浮动IP地址。
►部署模型使能
- 执行脚本命令部署模型使能;
- 查看模型使能安装状态。
►部署应用使能
- 执行脚本命令部署应用使能;
- 查看POD状态;
- 上传模型权重文件,填写模型元信息,进行模型部署;
- 访问ModelEngine对接模型,配置应用,创建对话助手应用;
- 测试对话。
3、知识库问答效果对比
(1)场景设置
我们构造了一篇企业知识文档,其中含有大量无意义的HTML标签和重复的段落。我们分别使用开源工具链(如Dify+Ollama)和ModelEngine(数据使能模块)进行知识库构建,随后使用同样的问题进行问答,观察二者的实际效果差异。
(2)待处理的示例原始文档片段:
从图标对比可看出,上述内容包含大量重复的语句、冗余信息(页眉页脚)和HTML标签。
(3)测试问题
对比分析XYZ科技公司的使命是什么?
(4)知识库问答效果对比
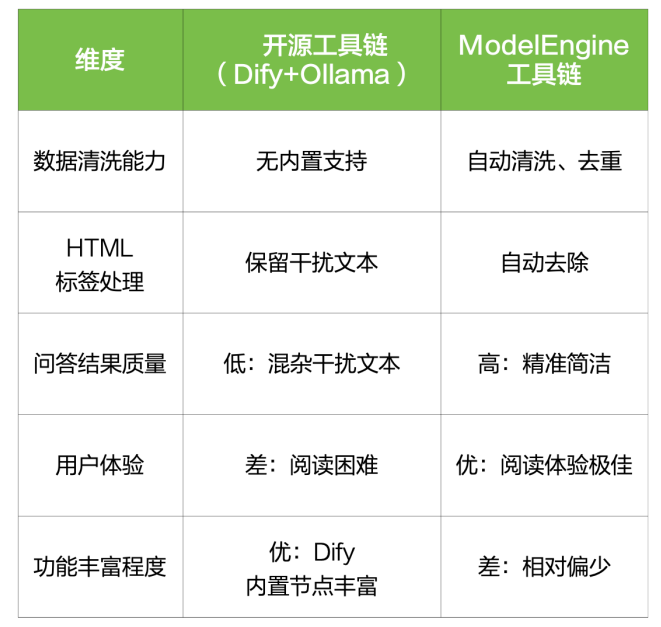
►开源工具链(Dify+Ollama)
知识库处理方式:文档导入知识库时未进行自动清洗,仅进行了基础的向量化处理;HTML标签、重复段落未自动去除。
问答效果:XYZ科技公司的使命是:“我们希望通过AI技术改变世界。Hidden content XYZ科技是一家领先的人工智能公司。XYZ科技官方页面联系我们:contact@xyz.com欢迎访问XYZ科技”。
结果分析:回答包含大量无意义内容和冗余信息;明显的未处理HTML标签文本混杂其中;用户体验较差,回答准确性低,干扰严重。
►昇腾平台(ModelEngine工具链)
知识库处理方式:使用数据使能模块,导入时自动完成HTML标签去除、冗余段落清洗、去重处理文本自动抽取并结构化,构建清洁的向量化知识库。
问答效果:XYZ科技公司的使命是:“我们希望通过AI技术改变世界。”
结果分析:回答干净、准确、无冗余;数据清洗明显提高了知识库问答的质量和用户体验;非常适合企业正式场景,体现了显著的实用价值。
基于以上测试,总结知识库效果差异如下:
三、对比分析
1、工具链理念对比:从“手工搭建”到“封装流水线”
通过前文详细拆解X86平台与昇腾平台上DeepSeek一体机的部署流程,我们可以发现,两种生态在底层架构、工具链风格、使用路径上呈现出显著差异。
在X86平台下,我们主要依赖开源工具链,如Ollama、Docker、Dify、NVIDIA Container Toolkit进行模型加载和服务封装。这种方式提供了极高的灵活性,用户可以自主选择模型格式、AI框架、显存分配、API风格、模型微调等配置方式,就像在一个开放式工作台上拼装积木,每一块组件都可以替换、组合、调优。
在昇腾平台采用的ModelEngine工具链则体现出另一种思路。ModelEngine本质上是一套集成了模型管理、推理服务、编排平台、数据接入的整体系统,从安装部署到模型上线、接口调用形成了封闭但标准的流水线工厂。对部署者而言,就像接收一套组装完毕、调试完善的智能家具,不需要焊枪,只要拧螺丝。
2、关键能力对比表
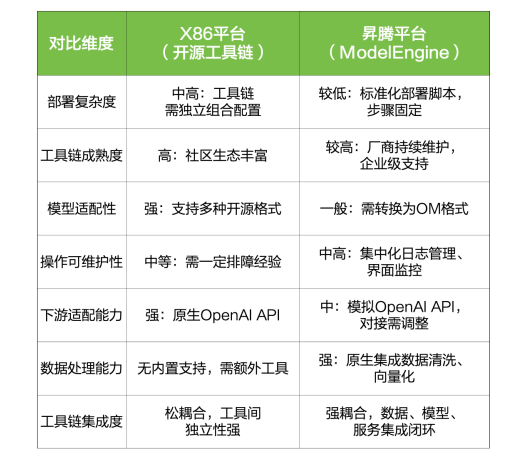
结合前文提到的5项评估维度,同时结合2项ModelEngine新增功能,对两套软硬件生态进行对比,结果如上图。
结合上述对比,我简略总结了以下实践体验总结:
X86方案体验关键词:“自由搭配”、“可控演化”、“高度定制”
►适合研发团队较强、需要快速试错的项目;
►部署过程中对系统权限、包版本、NVIDIA驱动细节有较高要求;
►灵活性强,但可能存在“踩坑”和维护负担。
昇腾方案体验关键词:“流程封装”、“稳定上线”、“交付可控”
►适合交付场景、企业运维团队或需要批量标准部署的客户;
►部署路径固定清晰,有厂商脚本支持、安装顺序固化;
►工具链闭环,系统资源利用明确,运行状态可观测。
3、ModelEngine独特优势
(1)数据工程能力
在实际企业场景中,利用自身数据构建高质量知识库对接模型是实现AI模型有效应用的基础环节。目前开源工具链(如Ollama、Dify、LangChain、Haystack等)已经能够很好地完成基础的知识库构建任务,例如:支持文档上传(PDF、DOCX、TXT等);实现文本分块和向量嵌入(向量数据库对接,如Faiss、Milvus、Pinecone等)提供标准化的知识库管理和调用API。
然而,上述开源工具链通常缺乏有效的数据清洗功能,特别是当文档内容质量参差不齐、包含大量冗余或噪声信息(页眉页脚、重复段落、格式混乱)时,开发者往往需要手动或额外编写数据清洗脚本进行预处理。这一环节明显增加了部署难度和数据工程成本。而ModelEngine工具链,在这一方面体现出明显的差异化能力:
内置的数据清洗模块:提供自动化的文档清洗能力,自动去除页眉页脚、重复内容、无效符号和冗余片段,使知识库数据干净、规范、高质量;
结构数据自动生成:文档清洗完成后,ModelEngine可进一步自动化生成结构化的知识(如标准QAPair、JSON格式),无需手动转换;
一站式数据流程管理:提供完整的数据处理流水线,从原始文档上传、自动化数据清洗到向量化知识库构建均可在同一工具链内完成,无需外部集成。
这种内置数据清洗功能的优势在于极大降低了人工干预和二次开发的负担,提高了部署效率与知识库质量,特别适合大型企业、政务机构、医疗系统等对数据质量和稳定性要求严格的场景。
(2)模型工程能力
ModelEngine工具链在模型工程领域构建了完整的“模型管理—训练—服务—评测”一体化流程,具备以下多种能力:
►模型管理
- 支持模型权重的上传与版本化管理;
- 支持模型量化格式转换(WA4/WA8/WA16)。
►模型训练
- 支持全参数训练与LoRA微调方式;
- 支持TP(Tensor Parallel)、PP(Pipeline Parallel)、DP(Data Parallel)等分布式训练策略组合配置。
►模型服务部署
- 支持分布式推理资源配置与弹性调度,支持推理服务超参配置与实例化部署;
- 支持模型推理服务统一注册、启停与监控,提升交付效率;
- 支持多种服务形式,包括公网API、北向接口。
►模型评测
- 提供统一的模型评测任务管理,支持BLEU、ROUGE、准确率等指标;
- 支持可视化结果分析与图表导出;
- 内置推理结果评估工具(MindIE Service Benchmark);
- 可自定义任务池进行多模型对比与效果预测。
(3)应用编排能力
从相关文档中,了解到ModelEngine与Dify工具一样,均支持零代码拖拽式编排,普通场景应用可一键生成;复杂企业级场景则可实现灵活编排与快速复用,大幅缩短AI应用落地周期。
(4)资源调度能力
基于容器的XPU池化与智能调度技术,通过碎片聚合、分时复用及弹性扩缩容策略,来提升XPU资源利用率。例如,借助Volcano调度引擎和vXPU切分技术,实现训练、推理、数据清洗任务的混合部署与动态资源分配,支持Qwen 32B任务实例数随负载从4扩至8。
四、总结
通过对X86平台(开源工具链)与昇腾平台(ModelEngine工具链)的横向对比分析,我们发现,两种平台分别体现了“生态开放性”与“一体化交付”的不同优势。X86平台工具链开放灵活,利于快速原型搭建,更适合敏捷研发团队;而ModelEngine则体现出强大的企业级交付能力。
未来,大模型部署生态将呈现开源生态与封装平台并存、互补的趋势,企业可根据自身数据治理、敏捷迭代和稳定交付的实际需求进行合理选择,最终推动AI能力的落地与价值释放。
*本文收录于《话数》用户专刊第2期
原文链接:https://www.oceanclub.org/cn/discuss/info/3770

